AI Model Catalog
Browse all available AI models across text, image, video, audio, speech, and upscale categories. Compare capabilities, costs, and parameters.
1022 models

bytedance/sdxl-lightning-4step
SDXL-Lightning by ByteDance: a fast text-to-image model that makes high-quality images in 4 steps

black-forest-labs/flux-schnell
The fastest image generation model tailored for local development and personal use
meta/meta-llama-3-8b-instruct
An 8 billion parameter language model from Meta, fine tuned for chat completions

salesforce/blip
Generate image captions
meta/meta-llama-3-70b-instruct
A 70 billion parameter language model from Meta, fine tuned for chat completions

openai/whisper
Convert speech in audio to text

falcons-ai/nsfw_image_detection
Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification

stability-ai/stable-diffusion
A latent text-to-image diffusion model capable of generating photo-realistic images given any text input

tencentarc/gfpgan
Practical face restoration algorithm for *old photos* or *AI-generated faces*

abiruyt/text-extract-ocr
A simple OCR Model that can easily extract text from an image.

google/nano-banana
Google's latest image editing model in Gemini 2.5

nightmareai/real-esrgan
Real-ESRGAN with optional face correction and adjustable upscale

stability-ai/sdxl
A text-to-image generative AI model that creates beautiful images

jaaari/kokoro-82m
Kokoro v1.0 - text-to-speech (82M params, based on StyleTTS2)

black-forest-labs/flux-1.1-pro
Faster, better FLUX Pro. Text-to-image model with excellent image quality, prompt adherence, and output diversity.
meta/meta-llama-3-8b
Base version of Llama 3, an 8 billion parameter language model from Meta.

sczhou/codeformer
Robust face restoration algorithm for old photos / AI-generated faces

black-forest-labs/flux-kontext-pro
A state-of-the-art text-based image editing model that delivers high-quality outputs with excellent prompt following and...

prunaai/z-image-turbo
Z-Image Turbo is a super fast text-to-image model of 6B parameters developed by Tongyi-MAI.

black-forest-labs/flux-dev
A 12 billion parameter rectified flow transformer capable of generating images from text descriptions

prunaai/flux-fast
This is the fastest Flux endpoint in the world.

jagilley/controlnet-scribble
Generate detailed images from scribbled drawings

prunaai/p-image-edit
A sub 1 second 0.01$ multi-image editing model built for production use cases. For image generation, check out p-image h...

yorickvp/llava-13b
Visual instruction tuning towards large language and vision models with GPT-4 level capabilities

google/nano-banana-pro
Google's state of the art image generation and editing model 🍌🍌

bytedance/seedream-4.5
Seedream 4.5: Upgraded Bytedance image model with stronger spatial understanding and world knowledge

andreasjansson/blip-2
Answers questions about images

openai/gpt-4o-mini
Low latency, low cost version of OpenAI's GPT-4o model

bytedance/seedream-4
Unified text-to-image generation and precise single-sentence editing at up to 4K resolution

philz1337x/clarity-upscaler
High resolution image Upscaler and Enhancer. Use at ClarityAI.co. A free Magnific alternative. Twitter/X: @philz1337x

vaibhavs10/incredibly-fast-whisper
whisper-large-v3, incredibly fast, powered by Hugging Face Transformers! 🤗

bytedance/hyper-flux-8step
Hyper FLUX 8-step by ByteDance

black-forest-labs/flux-1.1-pro-ultra
FLUX1.1 [pro] in ultra and raw modes. Images are up to 4 megapixels. Use raw mode for realism.

prunaai/flux-kontext-fast
Ultra fast flux kontext endpoint
nicolascoutureau/video-utils
No description available
meta/llama-2-7b-chat
A 7 billion parameter language model from Meta, fine tuned for chat completions

851-labs/background-remover
Remove backgrounds from images.

google/nano-banana-2
Google's fast image generation model with conversational editing, multi-image fusion, and character consistency

fofr/face-to-many
Turn a face into 3D, emoji, pixel art, video game, claymation or toy

lucataco/remove-bg
Remove background from an image

black-forest-labs/flux-pro
State-of-the-art image generation with top of the line prompt following, visual quality, image detail and output diversi...
openai/gpt-image-2
OpenAI's state-of-the-art image generation model. Create and edit images from text with strong instruction following, sh...

prunaai/p-image
A sub 1 second text-to-image model built for production use cases.

minimax/speech-02-turbo
Text-to-Audio (T2A) that offers voice synthesis, emotional expression, and multilingual capabilities. Designed for real-...

datacte/proteus-v0.2
Proteus v0.2 shows subtle yet significant improvements over Version 0.1. It demonstrates enhanced prompt understanding t...

fofr/sdxl-emoji
An SDXL fine-tune based on Apple Emojis

cjwbw/rembg
Remove images background

ai-forever/kandinsky-2.2
multilingual text2image latent diffusion model

meta/llama-2-70b-chat
A 70 billion parameter language model from Meta, fine tuned for chat completions

jagilley/controlnet-hough
Modify images using M-LSD line detection

black-forest-labs/flux-kontext-max
A premium text-based image editing model that delivers maximum performance and improved typography generation for transf...

qwen/qwen-image-edit-plus
The latest Qwen-Image’s iteration with improved multi-image editing, single-image consistency, and native support for Co...
lucataco/codeformer
Robust face restoration algorithm for old photos/AI-generated faces

alexgenovese/upscaler
GFPGAN aims at developing Practical Algorithms for Real-world Face and Object Restoration

tencentarc/photomaker
Create photos, paintings and avatars for anyone in any style within seconds.

bytedance/hyper-flux-16step
Hyper FLUX 16-step by ByteDance

lucataco/moondream2
moondream2 is a small vision language model designed to run efficiently on edge devices

thomasmol/whisper-diarization
⚡️ Blazing fast audio transcription with speaker diarization | Whisper Large V3 Turbo & pyannote 4.0 community-1 | word ...

prunaai/hidream-l1-fast
This is an optimised version of the hidream-l1 model using the pruna ai optimisation toolkit!

google/gemini-2.5-flash
Google’s hybrid “thinking” AI model optimized for speed and cost-efficiency

ideogram-ai/ideogram-v3-turbo
Turbo is the fastest and cheapest Ideogram v3. v3 creates images with stunning realism, creative designs, and consistent...

recraft-ai/recraft-v3
Recraft V3 (code-named red_panda) is a text-to-image model with the ability to generate long texts, and images in a wide...
wan-video/wan-2.2-i2v-fast
A very fast and cheap PrunaAI optimized version of Wan 2.2 A14B image-to-video

victor-upmeet/whisperx
Accelerated transcription, word-level timestamps and diarization with whisperX large-v3

comfyui/any-comfyui-workflow
Run any ComfyUI workflow. Guide: https://github.com/replicate/cog-comfyui

google/imagen-4
Google's Imagen 4 flagship model

black-forest-labs/flux-2-pro
High-quality image generation and editing with support for eight reference images

openai/clip
Official CLIP models, generate CLIP (clip-vit-large-patch14) text & image embeddings

black-forest-labs/flux-kontext-dev
Open-weight version of FLUX.1 Kontext

jingyunliang/swinir
Image Restoration Using Swin Transformer

ai-forever/kandinsky-2
text2img model trained on LAION HighRes and fine-tuned on internal datasets

usamaehsan/controlnet-1.1-x-realistic-vision-v2.0
controlnet 1.1 lineart x realistic-vision-v2.0 (updated to v5)

black-forest-labs/flux-dev-lora
A version of flux-dev, a text to image model, that supports fast fine-tuned lora inference

google/imagen-4-fast
Use this fast version of Imagen 4 when speed and cost are more important than quality

smoretalk/rembg-enhance
A background removal model enhanced with better matting

datacte/proteus-v0.3
ProteusV0.3: The Anime Update

deepseek-ai/deepseek-v3
DeepSeek-V3-0324 is the leading non-reasoning model, a milestone for open source

google/gemini-3-flash
Google's most intelligent model built for speed with frontier intelligence, superior search, and grounding

lucataco/xtts-v2
Coqui XTTS-v2: Multilingual Text To Speech Voice Cloning

yorickvp/llava-v1.6-mistral-7b
LLaVA v1.6: Large Language and Vision Assistant (Mistral-7B)

meta/llama-2-13b-chat
A 13 billion parameter language model from Meta, fine tuned for chat completions

pharmapsychotic/clip-interrogator
The CLIP Interrogator is a prompt engineering tool that combines OpenAI's CLIP and Salesforce's BLIP to optimize text pr...

zsxkib/mmaudio
Add sound to video using the MMAudio V2 model. An advanced AI model that synthesizes high-quality audio from video conte...

openai/gpt-5-nano
Fastest, most cost-effective GPT-5 model from OpenAI
meta/llama-4-maverick-instruct
A 17 billion parameter model with 128 experts

black-forest-labs/flux-2-klein-4b
Very fast image generation and editing model. 4 steps distilled, sub-second inference for production and near real-time ...

men1scus/birefnet
Bilateral Reference for High-Resolution Dichotomous Image Segmentation (CAAI AIR 2024)

lucataco/realistic-vision-v5.1
Implementation of Realistic Vision v5.1 with VAE

black-forest-labs/flux-fill-pro
Professional inpainting and outpainting model with state-of-the-art performance. Edit or extend images with natural, sea...

qwen/qwen-image-edit-2511
An enhanced version over Qwen-Image-Edit-2509, featuring multiple improvements including notably better consistency

bytedance/pulid
📖 PuLID: Pure and Lightning ID Customization via Contrastive Alignment
anthropic/claude-3.7-sonnet
The most intelligent Claude model and the first hybrid reasoning model on the market (claude-3-7-sonnet-20250219)

yorickvp/llava-v1.6-vicuna-13b
LLaVA v1.6: Large Language and Vision Assistant (Vicuna-13B)

black-forest-labs/flux-schnell-lora
The fastest image generation model tailored for fine-tuned use

recraft-ai/recraft-crisp-upscale
Designed to make images sharper and cleaner, Crisp Upscale increases overall quality, making visuals suitable for web us...
meta/llama-4-scout-instruct
A 17 billion parameter model with 16 experts

mv-lab/swin2sr
3.5 Million Runs! AI Photorealistic Image Super-Resolution and Restoration

lucataco/sdxl-controlnet
SDXL ControlNet - Canny

kwaivgi/kling-v2.1
Use Kling v2.1 to generate 5s and 10s videos in 720p and 1080p resolution from a starting image (image-to-video)

bytedance/seedance-1-lite
A video generation model that offers text-to-video and image-to-video support for 5s or 10s videos, at 480p and 720p res...

meta/musicgen
Generate music from a prompt or melody

openai/gpt-image-1.5
OpenAI's latest image generation model with better instruction following and adherence to prompts

cjwbw/anything-v4.0
high-quality, highly detailed anime-style Stable Diffusion models

bytedance/seedream-3
A text-to-image model with support for native high-resolution (2K) image generation

luma/photon
High-quality image generation model optimized for creative professional workflows and ultra-high fidelity outputs

black-forest-labs/flux-krea-dev
An opinionated text-to-image model from Black Forest Labs in collaboration with Krea that excels in photorealism. Create...

anthropic/claude-3.5-haiku
Anthropic's fastest, most cost-effective model, with a 200K token context window (claude-3-5-haiku-20241022)

fofr/flux-black-light
A flux lora fine-tuned on black light images

playgroundai/playground-v2.5-1024px-aesthetic
Playground v2.5 is the state-of-the-art open-source model in aesthetic quality

ideogram-ai/ideogram-v2-turbo
A fast image model with state of the art inpainting, prompt comprehension and text rendering.

black-forest-labs/flux-2-max
The highest fidelity image model from Black Forest Labs

cjwbw/real-esrgan
Real-ESRGAN: Real-World Blind Super-Resolution
bytedance/seedance-1.5-pro
A joint audio-video model that accurately follows complex instructions.

ideogram-ai/ideogram-v2
An excellent image model with state of the art inpainting, prompt comprehension and text rendering
kwaivgi/kling-v2.5-turbo-pro
Kling 2.5 Turbo Pro: Unlock pro-level text-to-video and image-to-video creation with smooth motion, cinematic depth, and...

methexis-inc/img2prompt
Get an approximate text prompt, with style, matching an image. (Optimized for stable-diffusion (clip ViT-L/14))

minimax/image-01
Minimax's first image model, with character reference support

bytedance/flux-pulid
⚡️FLUX PuLID: FLUX-dev based Pure and Lightning ID Customization via Contrastive Alignment🎭

minimax/speech-02-hd
Text-to-Audio (T2A) that offers voice synthesis, emotional expression, and multilingual capabilities. Optimized for high...
prunaai/p-video
Fast video generation with built-in draft mode for rapid creative iteration. Text-to-video, image-to-video, and audio-to...

flux-kontext-apps/multi-image-kontext-pro
An experimental model with FLUX Kontext Pro that can combine two input images

bytedance/seedream-5-lite
Seedream 5.0 lite: image generation with built-in reasoning, example-based editing, and deep domain knowledge

tstramer/material-diffusion
Stable diffusion fork for generating tileable outputs using v1.5 model

anthropic/claude-4-sonnet
Claude Sonnet 4 is a significant upgrade to 3.7, delivering superior coding and reasoning while responding more precisel...

deepseek-ai/deepseek-r1
A reasoning model trained with reinforcement learning, on par with OpenAI o1

ideogram-ai/ideogram-v3-quality
The highest quality Ideogram v3 model. v3 creates images with stunning realism, creative designs, and consistent styles

sdxl-based/realvisxl-v3-multi-controlnet-lora
RealVisXl V3 with multi-controlnet, lora loading, img2img, inpainting

ideogram-ai/ideogram-v2a
Like Ideogram v2, but faster and cheaper

snowflake/snowflake-arctic-instruct
An efficient, intelligent, and truly open-source language model

fofr/sticker-maker
Make stickers with AI. Generates graphics with transparent backgrounds.

google/imagen-3
Google's highest quality text-to-image model, capable of generating images with detail, rich lighting and beauty

stability-ai/stable-diffusion-3.5-large
A text-to-image model that generates high-resolution images with fine details. It supports various artistic styles and p...

piddnad/ddcolor
Towards Photo-Realistic Image Colorization via Dual Decoders

mistralai/mistral-7b-v0.1
A 7 billion parameter language model from Mistral.

adirik/interior-design
Realistic interior design with text and image inputs

stability-ai/stable-diffusion-3
A text-to-image model with greatly improved performance in image quality, typography, complex prompt understanding, and ...

daanelson/minigpt-4
A model which generates text in response to an input image and prompt.

rmokady/clip_prefix_caption
Simple image captioning model using CLIP and GPT-2

codeplugtech/face-swap
Advance Face Swap powered by pixalto.app

google/imagen-4-ultra
Use this ultra version of Imagen 4 when quality matters more than speed and cost

ibm-granite/granite-3.3-8b-instruct
Granite-3.3-8B-Instruct is a 8-billion parameter 128K context length language model fine-tuned for improved reasoning an...

fofr/face-to-sticker
Turn a face into a sticker

qwen/qwen-image-edit
Edit images using a prompt. This model extends Qwen-Image’s unique text rendering capabilities to image editing tasks, e...

openai/gpt-4.1-mini
Fast, affordable version of GPT-4.1

bytedance/seedance-1-pro
A pro version of Seedance that offers text-to-video and image-to-video support for 5s or 10s videos, at 480p and 1080p r...

pollinations/modnet
A deep learning approach to remove background & adding new background image

black-forest-labs/flux-2-klein-9b
4 step distilled version of FLUX.2 [klein]. A foundation model for maximum flexibility and control

tencentarc/photomaker-style
Create photos, paintings and avatars for anyone in any style within seconds. (Stylization version)

openai/gpt-image-1
A multimodal image generation model that creates high-quality images. You need to bring your own verified OpenAI key to ...

qwen/qwen-image
An image generation foundation model in the Qwen series that achieves significant advances in complex text rendering.

zsxkib/realistic-voice-cloning
Create song covers with any RVC v2 trained AI voice from audio files.

fofr/latent-consistency-model
Super-fast, 0.6s per image. LCM with img2img, large batching and canny controlnet

kwaivgi/kling-v1.6-standard
Generate 5s and 10s videos in 720p resolution at 30fps

black-forest-labs/flux-fill-dev
Open-weight inpainting model for editing and extending images. Guidance-distilled from FLUX.1 Fill [pro].

pseudoram/rvc-v2
Speech to speech with any RVC v2 trained AI voice

megvii-research/nafnet
Nonlinear Activation Free Network for Image Restoration

topazlabs/image-upscale
Professional-grade image upscaling, from Topaz Labs

zsxkib/blip-3
Blip 3 / XGen-MM, Answers questions about images ({blip3,xgen-mm}-phi3-mini-base-r-v1)

zsxkib/molmo-7b
allenai/Molmo-7B-D-0924, Answers questions and caption about images

google/gemini-3-pro
Google's most advanced reasoning Gemini model

orpatashnik/styleclip
Text-Driven Manipulation of StyleGAN Imagery

black-forest-labs/flux-2-dev
Quality image generation and editing with support for reference images

openai/gpt-5
OpenAI's new model excelling at coding, writing, and reasoning.

google/gemini-2.5-flash-image
Google's latest image generation model in Gemini 2.5
xai/grok-imagine-video
Generate videos using xAI's Grok Imagine Video model

microsoft/bringing-old-photos-back-to-life
Bringing Old Photos Back to Life

openai/gpt-4.1-nano
Fastest, most cost-effective GPT-4.1 model from OpenAI

google/gemini-3.1-pro
Google's most intelligent model, with improved reasoning and a new medium thinking level

openai/gpt-5-mini
Faster version of OpenAI's flagship GPT-5 model

nvidia/sana-sprint-1.6b
SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillation

black-forest-labs/flux-depth-dev
Open-weight depth-aware image generation. Edit images while preserving spatial relationships.

philz1337x/controlnet-deliberate
Modify images with canny edge detection and Deliberate model twitter: @philz1337x

qwen/qwen3-235b-a22b-instruct-2507
Updated Qwen3 model for instruction following

prunaai/wan-2.2-image
This model generates beautiful cinematic 2 megapixel images in 3-4 seconds and is derived from the Wan 2.2 model through...

riffusion/riffusion
Stable diffusion for real-time music generation

recraft-ai/recraft-remove-background
Automated background removal for images. Tuned for AI-generated content, product photos, portraits, and design workflows

lucataco/ssd-1b
Segmind Stable Diffusion Model (SSD-1B) is a distilled 50% smaller version of SDXL, offering a 60% speedup while maintai...

minimax/speech-2.6-turbo
Low‑latency MiniMax Speech 2.6 Turbo brings multilingual, emotional text-to-speech to Replicate with 300+ voices and rea...

zsxkib/instant-id
Make realistic images of real people instantly
kwaivgi/kling-v2.6-motion-control
Enables precise control of character actions and expressions from a reference image.

fermatresearch/sdxl-controlnet-lora
'''Last update: Now supports img2img.''' SDXL Canny controlnet with LoRA support.

fermatresearch/magic-image-refiner
A better alternative to SDXL refiners, providing a lot of quality and detail. Can also be used for inpainting or upscali...

flux-kontext-apps/restore-image
Use FLUX Kontext to restore, fix scratches and damage, and colorize old photos

stability-ai/stable-diffusion-3.5-large-turbo
A text-to-image model that generates high-resolution images with fine details. It supports various artistic styles and p...

lucataco/hotshot-xl
😊 Hotshot-XL is an AI text-to-GIF model trained to work alongside Stable Diffusion XL

lucataco/frame-extractor
Extract the first or last frame from any video file as a high-quality image

bytedance/seedance-2.0
ByteDance's multimodal video generation model with native audio, multimodal reference inputs, and intelligent duration c...
meta/meta-llama-3-70b
Base version of Llama 3, a 70 billion parameter language model from Meta.

lucataco/sdxl-clip-interrogator
CLIP Interrogator for SDXL optimizes text prompts to match a given image

jagilley/controlnet-canny
Modify images using canny edge detection

topazlabs/video-upscale
Video Upscaling from Topaz Labs

lucataco/qwen-vl-chat
A multimodal LLM-based AI assistant, which is trained with alignment techniques. Qwen-VL-Chat supports more flexible int...
bytedance/seedance-1-pro-fast
A faster and cheaper version of Seedance 1 Pro

kwaivgi/kling-v1.6-pro
Generate 5s and 10s videos in 1080p resolution

fofr/become-image
Adapt any picture of a face into another image

zylim0702/qr_code_controlnet
ControlNet QR Code Generator: Simplify QR code creation for various needs using ControlNet's user-friendly neural interf...

ibm-granite/granite-3.1-8b-instruct
Granite-3.1-8B-Instruct is a lightweight and open-source 8B parameter model is designed to excel in instruction followin...

pixverse/pixverse-v5
Create 5s-8s videos with enhanced character movement, visual effects, and exclusive 1080p-8s support. Optimized for anim...

prunaai/p-image-upscale
Fastest image upscaler in the world (<1s) supporting outputs up to 128 MP. contact us for dedicated endpoints.

qwen/qwen-edit-multiangle
Camera-aware edits for Qwen/Qwen-Image-Edit-2509 with Lightning + multi-angle LoRA

runwayml/gen4-image
Runway's Gen-4 Image model with references. Use up to 3 reference images to create the exact image you need. Capture eve...

qwen/qwen3-tts
A unified Text-to-Speech demo featuring three powerful modes: Voice, Clone and Design

jagilley/controlnet-depth2img
Modify images using depth maps

usamaehsan/controlnet-x-ip-adapter-realistic-vision-v5
Inpainting || multi-controlnet || single-controlnet || ip-adapter || ip adapter face || ip adapter plus || No ip adapter

chenxwh/cogvlm2-video
CogVLM2: Visual Language Models for Image and Video Understanding
wan-video/wan-2.2-5b-fast
The fastest Wan 2.2 text-to-image and image-to-video model
google/veo-3.1-fast
New and improved version of Veo 3 Fast, with higher-fidelity video, context-aware audio and last frame support

minimax/video-01
Generate 6s videos with prompts or images. (Also known as Hailuo). Use a subject reference to make a video with a charac...

meta/llama-2-7b
Base version of Llama 2 7B, a 7 billion parameter language model
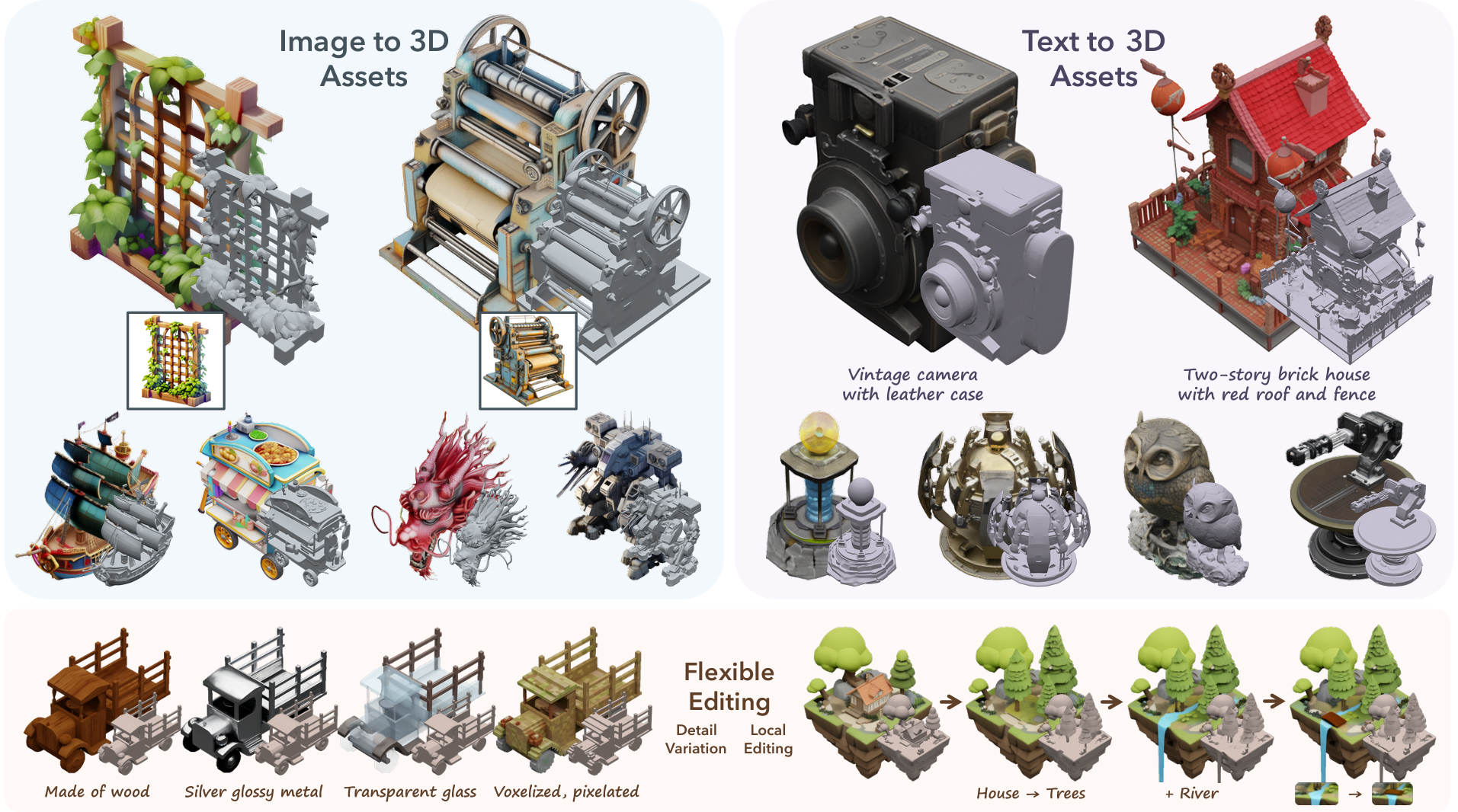
firtoz/trellis
A powerful 3D asset generation model

fermatresearch/high-resolution-controlnet-tile
UPDATE: new upscaling algorithm for a much improved image quality. Fermat.app open-source implementation of an efficient...

anthropic/claude-4.5-sonnet
Claude Sonnet 4.5 is the best coding model to date, with significant improvements across the entire development lifecycl...

cjwbw/bigcolor
Colorization using a Generative Color Prior for Natural Images

jagilley/controlnet-hed
Modify images using HED maps

openai/gpt-oss-20b
20b open-weight language model from OpenAI

google/upscaler
Upscale images 2x or 4x times

adirik/realvisxl-v3.0-turbo
Photorealism with RealVisXL V3.0 Turbo based on SDXL

aaronaftab/mirage-ghibli
Ghiblify any image, 10x cheaper/faster than GPT 4o

openai/gpt-image-1-mini
A cost-efficient version of GPT Image 1

tencentarc/vqfr
Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder

recraft-ai/recraft-vectorize
Convert raster images to high-quality SVG format with precision and clean vector paths, perfect for logos, icons, and sc...
yoyo-nb/thin-plate-spline-motion-model
Thin-Plate Spline Motion Model for Image Animation

rafaelgalle/whisper-diarization-advanced
Ultra-fast, customizable speech-to-text and speaker diarization for noisy, multi-speaker audio. Includes advanced noise ...

google-research/maxim
Multi-Axis MLP for Image Processing

google/imagen-3-fast
A faster and cheaper Imagen 3 model, for when price or speed are more important than final image quality

ibm-granite/granite-8b-code-instruct-128k
Join the Granite community where you can find numerous recipe workbooks to help you get started with a wide variety of u...

pnyompen/sd-controlnet-lora
SD1.5 Canny controlnet with LoRA support.
kwaivgi/kling-v3-omni-video
Kling Video 3.0 Omni: Unified multimodal video generation with reference images, video editing, native audio, and multi-...

ideogram-ai/ideogram-character
Generate consistent characters from a single reference image. Outputs can be in many styles. You can also use inpainting...
andreasjansson/tile-morph
Create tileable animations with seamless transitions

openai/gpt-5-structured
GPT-5 with support for structured outputs, web search and custom tools

openai/gpt-4o
OpenAI's high-intelligence chat model

minimax/music-01
Quickly generate up to 1 minute of music with lyrics and vocals in the style of a reference track

philz1337x/crystal-upscaler
High-precision image upscaler optimized for portraits, faces and products. One of the upscale modes powered by Clarity A...
google/veo-3.1
New and improved version of Veo 3, with higher-fidelity video, context-aware audio, reference image and last frame suppo...

bria/remove-background
Bria AI's remove background model

cjwbw/rudalle-sr
Real-ESRGAN super-resolution model from ruDALL-E

deepseek-ai/deepseek-v3.1
Latest hybrid thinking model from Deepseek

arielreplicate/deoldify_image
Add colours to old images

replicate/train-rvc-model
Train your own custom RVC model

ibm-granite/granite-3.2-8b-instruct
Granite-3.2-8B-Instruct is a 8-billion parameter 128K context length language model fine-tuned for reasoning and instruc...

codeplugtech/background_remover
Remove background from image

wavespeedai/wan-2.1-i2v-480p
Accelerated inference for Wan 2.1 14B image to video, a comprehensive and open suite of video foundation models that pus...

qwen/qwen-image-edit-plus-lora
Qwen Image Edit 2509 LoRA explorer, uses HuggingFace URLs to load any safetensor

meta/llama-2-70b
Base version of Llama 2, a 70 billion parameter language model from Meta.

ibm-granite/granite-3.0-2b-instruct
Granite-3.0-2B-Instruct is a lightweight and open-source 2B parameter model designed to excel in instruction following t...

black-forest-labs/flux-canny-pro
Professional edge-guided image generation. Control structure and composition using Canny edge detection

andreasjansson/illusion
Monster Labs' control_v1p_sd15_qrcode_monster ControlNet on top of SD 1.5

openai/o4-mini
OpenAI's fast, lightweight reasoning model

ideogram-ai/ideogram-v3-balanced
Balance speed, quality and cost. Ideogram v3 creates images with stunning realism, creative designs, and consistent styl...

ideogram-ai/ideogram-v2a-turbo
Like Ideogram v2 turbo, but now faster and cheaper

recraft-ai/recraft-v3-svg
Recraft V3 SVG (code-named red_panda) is a text-to-image model with the ability to generate high quality SVG images incl...

lucataco/qwen2-vl-7b-instruct
Latest model in the Qwen family for chatting with video and image models

bria/expand-image
Bria Expand expands images beyond their borders in high quality. Resizing the image by generating new pixels to expand t...
minimax/hailuo-02
Hailuo 2 is a text-to-video and image-to-video model that can make 6s or 10s videos at 768p (standard) or 1080p (pro). I...

recraft-ai/recraft-20b
Affordable and fast images

jagilley/controlnet-normal
Modify images using normal maps
lucataco/animate-diff
Animate Your Personalized Text-to-Image Diffusion Models

lucataco/real-esrgan-video
Real-ESRGAN Video Upscaler
kwaivgi/kling-v3-motion-control
Kling 3.0 motion control: transfer motion from a reference video to any character image with improved consistency and qu...

luma/reframe-image
Change the aspect ratio of any photo using AI (not cropping)

suno-ai/bark
🔊 Text-Prompted Generative Audio Model

black-forest-labs/flux-redux-dev
Open-weight image variation model. Create new versions while preserving key elements of your original.

black-forest-labs/flux-2-flex
Max-quality image generation and editing with support for ten reference images

bria/eraser
SOTA Object removal, enables precise removal of unwanted objects from images while maintaining high-quality outputs. Tra...

anotherjesse/zeroscope-v2-xl
Zeroscope V2 XL & 576w

luma/photon-flash
Accelerated variant of Photon prioritizing speed while maintaining quality

black-forest-labs/flux-depth-pro
Professional depth-aware image generation. Edit images while preserving spatial relationships.

j-min/clip-caption-reward
Fine-grained Image Captioning with CLIP Reward

codeslake/ifan-defocus-deblur
Removes defocus blur in an image

openai/gpt-5.2
The best model for coding and agentic tasks across industries
pixverse/lipsync
Generate realistic lipsync animations from audio for high-quality synchronization

openai/gpt-4.1
OpenAI's Flagship GPT model for complex tasks.

leonardoai/lucid-origin
Artistic and high-quality visuals with improved prompt adherence, diversity, and definition

bytedance/bagel
🥯ByteDance Seed's Bagel Unified multimodal AI that generates images, edits images, and understands images in one 7B par...
deforum/deforum_stable_diffusion
Animating prompts with stable diffusion

black-forest-labs/flux-kontext-dev-lora
FLUX.1 Kontext[dev] image editing model for running lora finetunes
kwaivgi/kling-v3-video
Kling Video 3.0: Generate cinematic videos up to 15 seconds with multi-shot control, native audio, and improved consiste...
joehoover/instructblip-vicuna13b
An instruction-tuned multi-modal model based on BLIP-2 and Vicuna-13B
runwayml/gen4-aleph
A new way to edit, transform and generate video

ibm-granite/granite-vision-3.3-2b
Granite-vision-3.3-2b is a compact and efficient vision-language model, specifically designed for visual document unders...

pixverse/pixverse-v4.5
Quickly make 5s or 8s videos at 540p, 720p or 1080p. It has enhanced motion, prompt coherence and handles complex action...

openai/dall-e-3
An AI system that can create realistic images and art from a description in natural language.

nvidia/sana
A fast image model with wide artistic range and resolutions up to 4096x4096

openai/gpt-5.1
The best model for coding and agentic tasks with configurable reasoning effort.
shreejalmaharjan-27/tiktok-short-captions
Generate Tiktok-Style Captions powered by Whisper (GPU)

openai/gpt-oss-120b
120b open-weight language model from OpenAI

lucataco/dreamshaper-xl-turbo
DreamShaper is a general purpose SD model that aims at doing everything well, photos, art, anime, manga. It's designed t...

ibm-granite/granite-4.0-h-small
Granite-4.0-H-Small is a 32B parameter long-context instruct model finetuned from Granite-4.0-H-Small-Base using a combi...

openai/sora-2
OpenAI's Flagship video generation with synced audio

resemble-ai/chatterbox
Generate expressive, natural speech. Features unique emotion control, instant voice cloning from short audio, and built-...

jingyunliang/hcflow-sr
Image Super-Resolution

flux-kontext-apps/multi-image-kontext-max
An experimental FLUX Kontext model that can combine two input images

google/veo-3
Sound on: Google’s flagship Veo 3 text to video model, with audio

xinntao/esrgan
Image 4x super-resolution

fofr/sdxl-multi-controlnet-lora
Multi-controlnet, lora loading, img2img, inpainting

fofr/color-matcher
Color match and white balance fixes for images

meta/llama-2-13b
Base version of Llama 2 13B, a 13 billion parameter language model
bytedance/seedance-2.0-fast
A faster variant of Seedance 2.0 for quicker video generation with multimodal inputs and native audio.

black-forest-labs/flux-canny-dev
Open-weight edge-guided image generation. Control structure and composition using Canny edge detection.

google/lyria-3
Generate 30-second music clips from text prompts or images with Lyria 3, Google's music generation model

google/gemini-3.1-flash-tts
Google's fast, expressive text-to-speech model with 30 voices and 70+ language support

minimax/speech-2.8-turbo
Minimax Speech 2.8 Turbo: Turn text into natural, expressive speech with voice cloning, emotion control, and support for...
wan-video/wan-2.5-i2v
Alibaba Wan 2.5 Image to video generation with background audio
wan-video/wan-2.2-t2v-fast
A very fast and cheap PrunaAI optimized version of Wan 2.2 A14B text-to-video

cjwbw/supir
Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild. This version uses LLaVA-13b for captioning.

awerks/neon-tts
NeonAI Coqui AI TTS Plugin.

minimax/speech-2.6-hd
MiniMax Speech 2.6 HD delivers studio-quality multilingual text-to-audio on Replicate with nuanced prosody, subtitle exp...

wavespeedai/wan-2.1-t2v-480p
Accelerated inference for Wan 2.1 14B text to video, a comprehensive and open suite of video foundation models that push...

prunaai/p-image-edit-lora
Use trained LoRAs from the https://replicate.com/prunaai/p-image-edit-trainer. Find or contribute LoRAs here: https://hu...
kwaivgi/kling-v2.6
Kling 2.6 Pro: Top-tier image-to-video with cinematic visuals, fluid motion, and native audio generation

ibm-granite/granite-3.0-8b-instruct
Granite-3.0-8B-Instruct is a lightweight and open-source 8B parameter model is designed to excel in instruction followin...
flux-kontext-apps/change-haircut
Quickly change someone's hair style and hair color, powered by FLUX.1 Kontext [pro]

flux-kontext-apps/multi-image-list
FLUX Kontext max with list input for multiple images

minimax/video-01-live
An image-to-video (I2V) model specifically trained for Live2D and general animation use cases

jagilley/controlnet-pose
Modify images with humans using pose detection
afiaka87/tortoise-tts
Generate speech from text, clone voices from mp3 files. From James Betker AKA "neonbjb".
google/veo-3-fast
A faster and cheaper version of Google’s Veo 3 video model, with audio

jagilley/controlnet-seg
Modify images using semantic segmentation

fewjative/ultimate-sd-upscale
Ultimate SD Upscale with ControlNet Tile

lightricks/ltx-video
LTX-Video is the first DiT-based video generation model capable of generating high-quality videos in real-time. It produ...

yangxy/gpen
Blind Face Restoration in the Wild

bria/image-3.2
Commercial-ready, trained entirely on licensed data, text-to-image model. With only 4B parameters provides exceptional a...

cjwbw/sadtalker
Stylized Audio-Driven Single Image Talking Face Animation
cjwbw/damo-text-to-video
Multi-stage text-to-video generation

cjwbw/videocrafter
VideoCrafter2: Text-to-Video and Image-to-Video Generation and Editing
bytedance/omni-human
Turns your audio/video/images into professional-quality animated videos
replicate/flan-t5-xl
A language model by Google for tasks like classification, summarization, and more

flux-kontext-apps/cartoonify
Turn your image into a cartoon with FLUX.1 Kontext [pro]

appmeloncreator/platmoji-beta
This is an emoji generator fine tuned with Flux. (btw thx so much for the support on this)

stability-ai/stablelm-tuned-alpha-7b
7 billion parameter version of Stability AI's language model

inworld/realtime-tts-1.5-max
Highest-quality realtime text-to-speech with <200ms latency, emotion control, and 15-language support

cjwbw/vqfr
Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder

resemble-ai/chatterbox-turbo
The fastest open source TTS model without sacrificing quality.

zsxkib/diffbir
✨DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior

qwen/qwen-image-2512
Qwen Image 2512 is an improved version of Qwen Image with more realistic human generation, finer textures, and stronger ...

google-deepmind/gemma-2b-it
2B instruct version of Google’s Gemma model

adirik/flux-cinestill
Flux lora, use "CNSTLL" to trigger

lucataco/open-dalle-v1.1
A unique fusion that showcases exceptional prompt adherence and semantic understanding, it seems to be a step above base...

adirik/styletts2
Generates speech from text

lucataco/florence-2-base
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks

ali-vilab/i2vgen-xl
RESEARCH/NON-COMMERCIAL USE ONLY: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models

lucataco/apollo-7b
Apollo 7B - An Exploration of Video Understanding in Large Multimodal Models

flux-kontext-apps/text-removal
Remove all text from an image with FLUX.1 Kontext

bytedance/dreamina-3.1
4MP text-to-image generation with enhanced cinematic-quality image generation with precise style control, improved text ...

recraft-ai/recraft-20b-svg
Affordable and fast vector images

cjwbw/supir-v0q
Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild. This is the SUPIR-v0Q model and does NOT use...
andreasjansson/stable-diffusion-animation
Animate Stable Diffusion by interpolating between two prompts

tencent/hunyuan-video
A state-of-the-art text-to-video generation model capable of creating high-quality videos with realistic motion from tex...

nightmareai/latent-sr
Upscale images with the latent diffusion superresolution model

xai/grok-text-to-speech
Convert text to natural-sounding speech with xAI's Grok TTS. 5 voices, 20 languages, expressive speech tags, and high-fi...

black-forest-labs/flux-1.1-pro-ultra-finetuned
Inference model for FLUX 1.1 [pro] Ultra using custom `finetune_id`. Supports 4MP images and raw mode for realism

bytedance/latentsync
LatentSync: generate high-quality lip sync animations

ibm-granite/granite-20b-code-instruct-8k
Join the Granite community where you can find numerous recipe workbooks to help you get started with a wide variety of u...

bria/increase-resolution
Bria Increase resolution upscales the resolution of any image. It increases resolution using a dedicated upscaling metho...

runwayml/gen4-image-turbo
Gen-4 Image Turbo is cheaper and 2.5x faster than Gen-4 Image. An image model with references, use up to 3 reference ima...

lucataco/ace-step
A Step Towards Music Generation Foundation Model text2music

minimax/speech-2.8-hd
Minimax Speech 2.8 HD focuses on high-fidelity audio generation with features like studio-grade quality, flexible emotio...

reve/create
Image generation model from Reve

google/veo-2
State of the art video generation model. Veo 2 can faithfully follow simple and complex instructions, and convincingly s...

google/gemini-3.5-flash
Google's fast multimodal model with frontier reasoning across agents, coding, and long-context tasks

stability-ai/stable-diffusion-3.5-medium
2.5 billion parameter image model with improved MMDiT-X architecture

open-mmlab/pia
Personalized Image Animator

cswry/seesr
SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution
runwayml/gen4-turbo
Generate 5s and 10s 720p videos fast

cjwbw/seamless_communication
SeamlessM4T—Massively Multilingual & Multimodal Machine Translation

replicate/llama-7b
Transformers implementation of the LLaMA language model

flux-kontext-apps/face-to-many-kontext
Become a character, in style

anthropic/claude-4.5-haiku
Claude Haiku 4.5 gives you similar levels of coding performance but at one-third the cost and more than twice the speed

reve/edit
Image editing model from Reve

chigozienri/mediapipe-face
batch or individual face detection with mediapipe

openai/gpt-5.4
OpenAI's most capable frontier model for complex professional work, coding, and multi-step reasoning.

daanelson/whisperx
Accelerated transcription of audio using WhisperX

cuuupid/glm-4v-9b
GLM-4V is a multimodal model released by Tsinghua University that is competitive with GPT-4o and establishes a new SOTA ...
xai/grok-imagine-video-1.5
Image-to-video with synchronized audio using xAI's Grok Imagine Video 1.5 preview model

aleksa-codes/flux-ghibsky-illustration
Flux LoRA, use 'GHIBSKY style' to trigger generation, creates serene and enchanting landscapes with vibrant, surreal ski...

kwaivgi/kling-v2.0
Generate 5s and 10s videos in 720p resolution

fictions-ai/autocaption
Automatically add captions to a video

flux-kontext-apps/portrait-series
Create a series of portrait photos from a single image

openai/sora-2-pro
OpenAI's Most advanced synced-audio video generation

datacte/flux-aesthetic-anime
Flux lora, trained on the unique style and aesthetic of ghibli retro anime
kwaivgi/kling-v2.1-master
A premium version of Kling v2.1 with superb dynamics and prompt adherence. Generate 1080p 5s and 10s videos from text or...

wan-video/wan-2.7-image-pro
Generate and edit high-quality images with Alibaba's Wan 2.7 Pro with 4K output, thinking mode, text-to-image, multi-ima...

wavespeedai/wan-2.1-i2v-720p
Accelerated inference for Wan 2.1 14B image to video with high resolution, a comprehensive and open suite of video found...

chenxwh/openvoice
Updated to OpenVoice v2: Versatile Instant Voice Cloning

inworld/realtime-tts-1.5-mini
Ultra-fast, cost-efficient realtime text-to-speech with ~120ms latency and 15-language support

lucataco/trim-video
Simple tool to quickly trim a video or audio file

arielreplicate/robust_video_matting
extract foreground of a video
lightricks/ltx-2-fast
Ideal for rapid ideation and mobile workflows. Perfect for creators who need instant feedback, real-time previews, or hi...

mirelo/video-to-sfx-v1.5
Generate synced sounds for any video and return it with its new soundtrack - now enhanced in version 1.5 for improved so...

anthropic/claude-opus-4.7
Anthropic's most capable model with a step-change improvement in agentic coding, better vision, and stronger multi-step ...

minimax/video-01-director
Generate videos with specific camera movements
m1guelpf/whisper-subtitles
Generate subtitles from an audio file, using OpenAI's Whisper model.

flux-kontext-apps/professional-headshot
Create a professional headshot photo from any single image
wan-video/wan2.6-i2v-flash
Image-to-video generation with optional audio, multi-shot narrative support, and faster inference

black-forest-labs/flux-redux-schnell
Fast, efficient image variation model for rapid iteration and experimentation.

xai/grok-imagine-image-quality
xAI's higher-quality image model with sharper details, better text rendering, and 2k output
wan-video/wan-2.2-s2v
Generate a video from an audio clip and a reference image

cjwbw/rmgb
Background removal model developed by BRIA.AI, trained on a carefully selected dataset and is available as an open-sourc...

fofr/tooncrafter
Create videos from illustrated input images
meta/llama-guard-4-12b
No description available

google/lyria-2
Lyria 2 is a music generation model that produces 48kHz stereo audio through text-based prompts

andreasjansson/musicgen-looper
Generate fixed-bpm loops from text prompts
xai/grok-imagine-r2v
Generate videos guided by reference images using xAI's Grok Imagine Video model

zsxkib/animate-diff
🎨 AnimateDiff (w/ MotionLoRAs for Panning, Zooming, etc): Animate Your Personalized Text-to-Image Diffusion Models with...
luma/ray-flash-2-540p
Generate 5s and 9s 540p videos, faster and cheaper than Ray 2
prunaai/p-video-avatar
p-video-avatar is the fastest and cheapest avatar/lipsync video model on the market.

meta/sam-2-video
SAM 2: Segment Anything v2 (for videos)

sdsgitaccount/flux-gmoveus
Flux lora, use "GMOVEUS" to trigger movement MEME
joehoover/mplug-owl
An instruction-tuned multimodal large language model that generates text based on user-provided prompts and images
minimax/hailuo-2.3
A high-fidelity video generation model optimized for realistic human motion, cinematic VFX, expressive characters, and s...

zsxkib/film-frame-interpolation-for-large-motion
FILM: Frame Interpolation for Large Motion, In ECCV 2022.

minimax/music-1.5
Music-1.5: Full-length songs (up to 4 mins) with natural vocals & rich instrumentation
minimax/hailuo-02-fast
A low cost and fast version of Hailuo 02. Generate 6s and 10s videos in 512p

wan-video/wan-2.7-image
Generate and edit images with Alibaba's Wan 2.7
pixverse/pixverse-v6
PixVerse's flagship video generation model. Generate cinematic videos with synchronized audio, multi-shot sequences, and...

black-forest-labs/flux-2-klein-4b-base
Un-distilled version of FLUX.2 [klein]. Optimized for fine-tuning, customization, and post-training workflows
wan-video/wan-2.5-i2v-fast
Wan 2.5 image-to-video, optimized for speed

tencent/hunyuan-image-3
A powerful native multimodal model for image generation (PrunaAI squeezed)

lucataco/deepseek-ocr
Convert documents to markdown, extract raw text, and locate specific content

fermatresearch/magic-style-transfer
Restyle an image with the style of another one. I strongly suggest to upscale the results with Clarity AI

bria/generate-background
Bria Background Generation allows for efficient swapping of backgrounds in images via text prompts or reference image, d...

juergengunz/ultimate-portrait-upscale
Upscale Portrait Images with ControlNet Tile

reve/edit-fast
Reve's fast image edit model at only $0.01 per edit

zsxkib/ic-light-background
🖼️✨Background images + prompts to auto-magically relights your images (+normal maps🗺️)
datalab-to/marker
Convert PDF to markdown + JSON quickly with high accuracy

prunaai/hidream-l1-dev
This is an optimised version of the hidream-l1-dev model using the pruna ai optimisation toolkit!
sync/lipsync-2-pro
Studio-grade lipsync in minutes, not weeks

wan-video/wan-2.2-i2v-a14b
Image-to-video at 720p and 480p with Wan 2.2 A14B

black-forest-labs/flux-2-klein-9b-base
Un-distilled version of FLUX.2 [klein]. A foundation model for maximum flexibility and control
minimax/hailuo-2.3-fast
A lower-latency image-to-video version of Hailuo 2.3 that preserves core motion quality, visual consistency, and styliza...

wan-video/wan-2.1-1.3b
Generate 5s 480p videos. Wan is an advanced and powerful visual generation model developed by Tongyi Lab of Alibaba Grou...

wan-video/wan-2.7-i2v
Generate videos from images, with support for first-and-last-frame control, clip continuation, and audio synchronization...
wan-video/wan-2.2-animate-replace
Use Wan 2.2 Animate to replace a character in a video scene

grandlineai/instant-id-photorealistic
InstantID : Zero-shot Identity-Preserving Generation in Seconds. Using Juggernaut-XL v8 as the base model to encourage p...
wan-video/wan-2.6-i2v
Alibaba Wan 2.6 image to video generation model

zsxkib/seedvr2
🔥 SeedVR2: one-step video & image restoration with 3B/7B hot‑swap and optional color fix 🎬✨

minimax/voice-cloning
Clone voices to use with Minimax's speech-02-hd and speech-02-turbo
tencent/hunyuan-3d-3.1
3D models with texture fidelity and geometry precision

luma/ray-flash-2-720p
Generate 5s and 9s 720p videos, faster and cheaper than Ray 2
wan-video/wan-2.5-t2v-fast
Wan 2.5 text-to-video, optimized for speed

cjwbw/night-enhancement
Unsupervised Night Image Enhancement

bingbangboom-lab/flux-dreamscape
Flux lora, use "BSstyle004" to trigger image generation

lucataco/pasd-magnify
(Academic and Non-commercial use only) Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalize...

davisbrown/flux-half-illustration
Flux lora, use "in the style of TOK" to trigger generation, creates half photo half illustrated elements
cjwbw/text2video-zero
Text-to-Image Diffusion Models are Zero-Shot Video Generators

reve/remix
Image generation model from Reve which handles multiple input reference images

google/veo-3.1-lite
Google's cost-efficient video generation model with native audio, optimized for high-volume applications

wan-video/wan2.1-with-lora
Run Wan2.1 14b or 1.3b with a lora

pixverse/pixverse-v4
Quickly generate smooth 5s or 8s videos at 540p, 720p or 1080p
veed/fabric-1.0
VEED Fabric 1.0 is an image-to-video API that turns any image into a talking video
bytedance/omni-human-1.5
A film-grade digital human model that generates realistic video from a single image, audio clip, and optional text promp...

x-lance/f5-tts
F5-TTS, the new state-of-the-art in open source voice cloning
sync/lipsync-2
Generate realistic lipsyncs with Sync Labs' 2.0 model

perceptron-ai-inc/isaac-0.1
an open-source, 2B-parameter model built for real-world applications

qwen/qwen-image-2
A next-generation image generation and editing model from Alibaba's Qwen team. Supports text-to-image and image editing ...

leonardoai/phoenix-1.0
Leonardo AI’s first foundational model produces images up to 5 megapixels (fast, quality and ultra modes)

lucataco/ip_adapter-sdxl-face
The image prompt adapter is designed to enable a pretrained text-to-image diffusion model to generate SDXL images with a...

arielreplicate/stable_diffusion_infinite_zoom
Use Runway's Stable-diffusion inpainting model to create an infinite loop video
lightricks/ltx-2.3-pro
High-fidelity video generation with portrait support, audio-to-video, retake, and extend. Text, image, and audio-driven ...

easel/ai-avatars
Use one or two face images to create AI avatars

luma/ray-2-720p
Generate 5s and 9s 720p videos

qwen/qwen-image-2-pro
The pro version of Qwen Image 2 from Alibaba's Qwen team. Enhanced text rendering, realism, and semantic adherence for h...

luma/reframe-video
Change the aspect ratio of any video up to 30 seconds long, outputs will be 720p

openai/gpt-4o-transcribe
A speech-to-text model that uses GPT-4o to transcribe audio

wavespeedai/wan-2.1-t2v-720p
Accelerated inference for Wan 2.1 14B text to video with high resolution, a comprehensive and open suite of video founda...
pbarker/gfpgan-video
GFPGAN for human face video upscaling

retro-diffusion/rd-fast
Fast pixel art image generation

prunaai/hidream-l1-full
This is an optimised version of the hidream-full model using the pruna ai optimisation toolkit!

lucataco/orpheus-3b-0.1-ft
Orpheus 3B - high quality, emotive Text to Speech

ismail-seleit/formfinder-flux
Flux version of FormFinder-XL - trained to create moody atmospheric images but is quite versatile to be mixed with other...
kwaivgi/kling-lip-sync
Add lip-sync to any video with an audio file or text

lucataco/videollama3-7b
VideoLLaMA 3: Frontier Multimodal Foundation Models for Video Understanding

apolinario/flux-tarot-v1
Flux lora, use "in the style of TOK a trtcrd tarot style" to trigger image generation

chenxwh/video-retalking
Audio-based Lip Synchronization for Talking Head Video
wan-video/wan-2.5-t2v
Alibaba Wan 2.5 text to video generation model

lucataco/ip-adapter-faceid
(Research only) IP-Adapter-FaceID can generate various style images conditioned on a face with only text prompts

halimalrasihi/flux-red-cinema
Cinematic Flux LoRA: Use "r3dcma" in your prompt to trigger this LoRA model.

lucataco/qwen2.5-omni-7b
Qwen2.5-Omni is an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, a...

fofr/face-swap-with-ideogram
Use ideogram-character to face-swap someone into a target image

meronym/speaker-transcription
Whisper transcription plus speaker diarization

retro-diffusion/rd-plus
High quality and authentic pixel art image generation

playht/play-dialog
End-to-end AI speech model designed for natural-sounding conversational speech synthesis, with support for context-aware...

awerks/whisperx
Fast automatic speech recognition (70x realtime with large-v2) with word-level timestamps and speaker diarization.
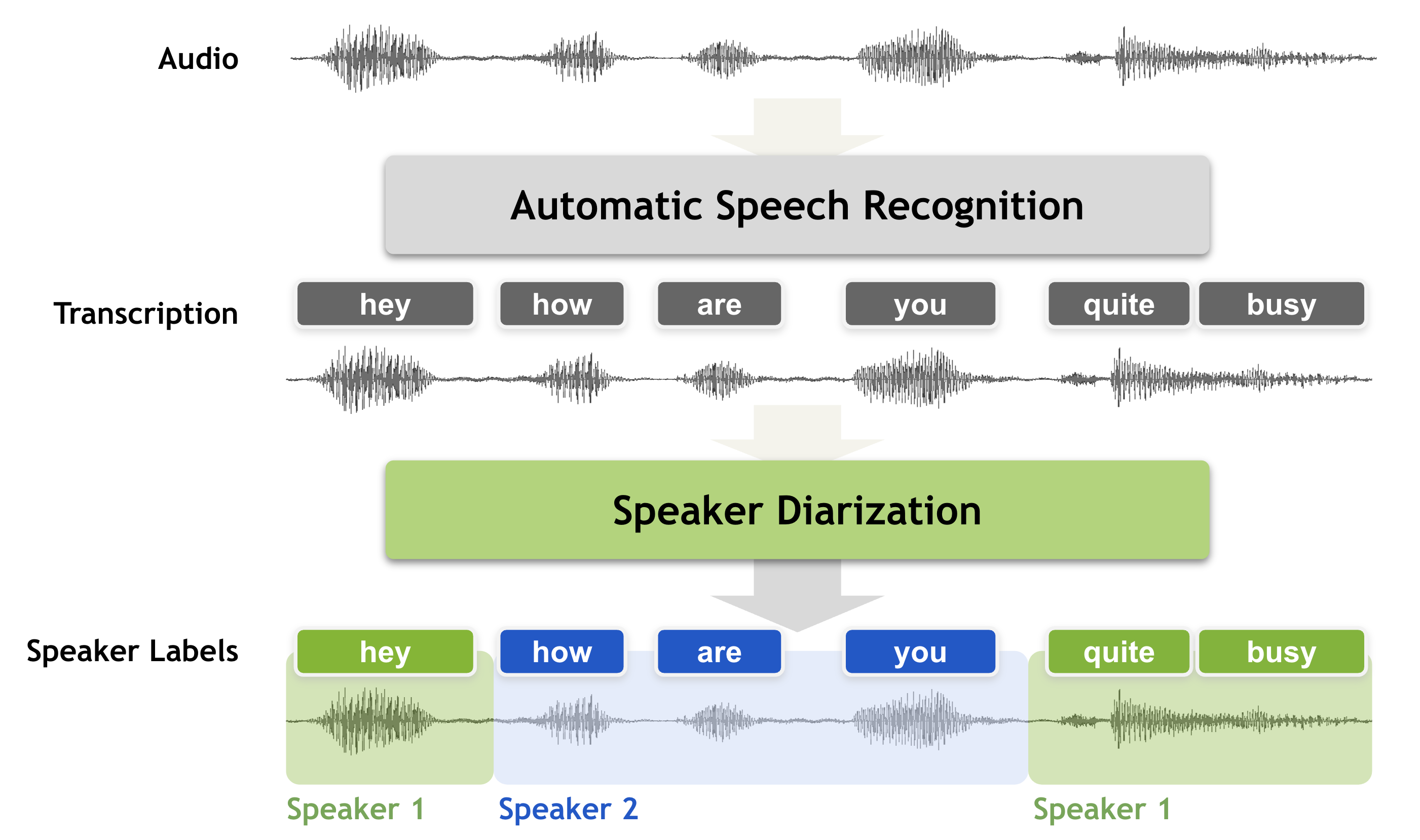
sabuhigr/sabuhi-model
Whisper AI with channel separation and speaker diarization
camenduru/tripo-sr
TripoSR: Fast 3D Object Reconstruction from a Single Image

levelsio/disposable-camera
Take photos with a disposable camera. Like this? Use this with yourself in it on my app PhotoAI.com
datalab-to/ocr
Detect and transcribe text in images with accurate bounding boxes, layout analysis, reding order, and table recognition,...
wan-video/wan-2.2-animate-animation
Use Wan 2.2 Animate to copy the motion of a video to another scene
lightricks/ltx-2.3-fast
Lightning-fast video generation with portrait support, camera controls, and synchronized audio. Up to 20 seconds at 1080...

lucataco/video-merge
Simple tool to merge together separate video snippets

nvidia/parakeet-rnnt-1.1b
🗣️ Nvidia + Suno.ai's speech-to-text conversion with high accuracy and efficiency 📝

resemble-ai/chatterbox-multilingual
Generate expressive, natural speech in 23 languages. Features instant voice cloning from short audio, emotion control, a...
lightricks/ltx-2-distilled
LTX-2: The first open source audio-video model
lucataco/video-audio-merge
merge a video and an audio file

stability-ai/stable-audio-2.5
Generate high-quality music and sound from text prompts
lightricks/ltx-2-pro
Delivers high visual fidelity with fast turnaround. Great for daily content creation, marketing teams, and iterative cre...

zsxkib/create-rvc-dataset
Create your own Realistic Voice Cloning (RVC v2) dataset using a YouTube link
fanyiy/flux-notion-illustration
Notion-style illustration

tencent/hunyuan-image-2.1
Generate high-quality 2K resolution images from text prompts

cjwbw/supir-v0f
Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild. This is the SUPIR-v0F model and does NOT use...

ibm-granite/granite-speech-3.3-8b
Granite-speech-3.3-8b is a compact and efficient speech-language model, specifically designed for automatic speech recog...

miike-ai/flux-ico
Create beautiful icons & emojis

igorriti/flux-360
Generate 360 panorama images.

fofr/kontext-make-person-real
A FLUX Kontext fine-tune to fix plastic AI skin textures

zsxkib/aura-sr-v2
AuraSR v2: Second-gen GAN-based Super-Resolution for real-world applications

adidoes/whisperx-video-transcribe
ASR from video URL based on whisperx using large-v2 model
kwaivgi/kling-avatar-v2
Create avatar videos with realistic humans, animals, cartoons, or stylized characters

sourceful/riverflow-2.0-pro
Agentic image model optimized for robust, high-precision generations supporting font control

sakemin/musicgen-remixer
Remix the music into another styles with MusicGen Chord

deepfates/deepfits_flux_dev
A fashion model

codeplugtech/object_remover
No description available

resemble-ai/chatterbox-pro
Generate expressive, natural speech with Resemble AI's Chatterbox.

google/lyria-3-pro
Generate full-length songs up to 3 minutes from text prompts or images with Lyria 3 Pro, Google's most capable music gen...

prunaai/vace-14b
This is a faster VACE-14B model, optimised with pruna, contact us for more at pruna.ai

recraft-ai/recraft-creative-upscale
Creative Upscale focuses on enhancing details and refining complex elements in the image. It doesn’t just increase resol...

moonshotai/kimi-k2.5
Moonshot AI's latest open model. It unifies vision and text, thinking and non-thinking modes, and single-agent and multi...

davisbrown/designer-architecture
Create professional architecture and interior designs

openai/o1
OpenAI's first o-series reasoning model

flux-kontext-apps/iconic-locations
Put yourself in an iconic location around the world from a single image

zsxkib/step1x-edit
✍️Step1X-Edit by stepfun-ai, Edit an image using text prompt📸

cjwbw/shap-e
Generating Conditional 3D Implicit Functions

levelsio/analog-film
Take photos in analog film style
alibaba/happyhorse-1.0
Alibaba's Happy Horse 1.0 generates videos from text prompts or animates a single image into video. Supports 720p and 10...

moonshotai/kimi-k2.6
Moonshot AI's frontier open model, built for long-horizon coding, agent swarms, and autonomous software engineering. 1 t...

ibm-granite/granite-4.1-8b
Granite-4.1-8B is a 8B parameter long-context instruct model finetuned from Granite-4.1-8B-Base using a combination of o...

fofr/video-morpher
Generate a video that morphs between subjects, with an optional style

raulduke9119/flux_realism
No description available

cjwbw/aniportrait-audio2vid
Audio-Driven Synthesis of Photorealistic Portrait Animations

mv-lab/instructir
High-Quality Image Restoration Following Human Instructions

tencent/hunyuan3d-2mv
Hunyuan3D-2mv is finetuned from Hunyuan3D-2 to support multiview controlled shape generation.

lucataco/fuyu-8b
Fuyu-8B is a multi-modal text and image transformer trained by Adept AI

lucataco/modelscope-facefusion
Auto fuse a user's face onto the template image, with a similar appearance to the user

aramintak/flux-softserve-anime
Flux lora, use "sftsrv style illustration" to trigger the image generation

qwen-edit-apps/qwen-image-edit-plus-lora-skin
Skin – Natural beauty retouch that enhances pores and tonal variation (no plastic skin) via the Skin LoRA.
character-ai/ovi-i2v
Ovi: generate videos with audio from image and text inputs
wan-video/wan-2.6-t2v
Alibaba Wan 2.6 text to video generation model

google/nano-banana-2-lite
Google's fastest image generation model — the lightweight, low-cost version of Nano Banana 2, for rapid creation and edi...

tudortotolici/newspaper_illustration
The "newspaper illustration" model specializes in creating black-and-white, cartoon-style drawings reminiscent of classi...

bytedance/seedream-5-pro
ByteDance's flagship text-to-image and image editing model, generating sharp 1K and 2K images from text or up to 10 refe...

bria/genfill
Bria GenFill enables high-quality object addition or visual transformation. Trained exclusively on licensed data for saf...

fofr/kontext-old-and-damaged
Use this kontext fine-tune to turn any photo into an old and damaged photo
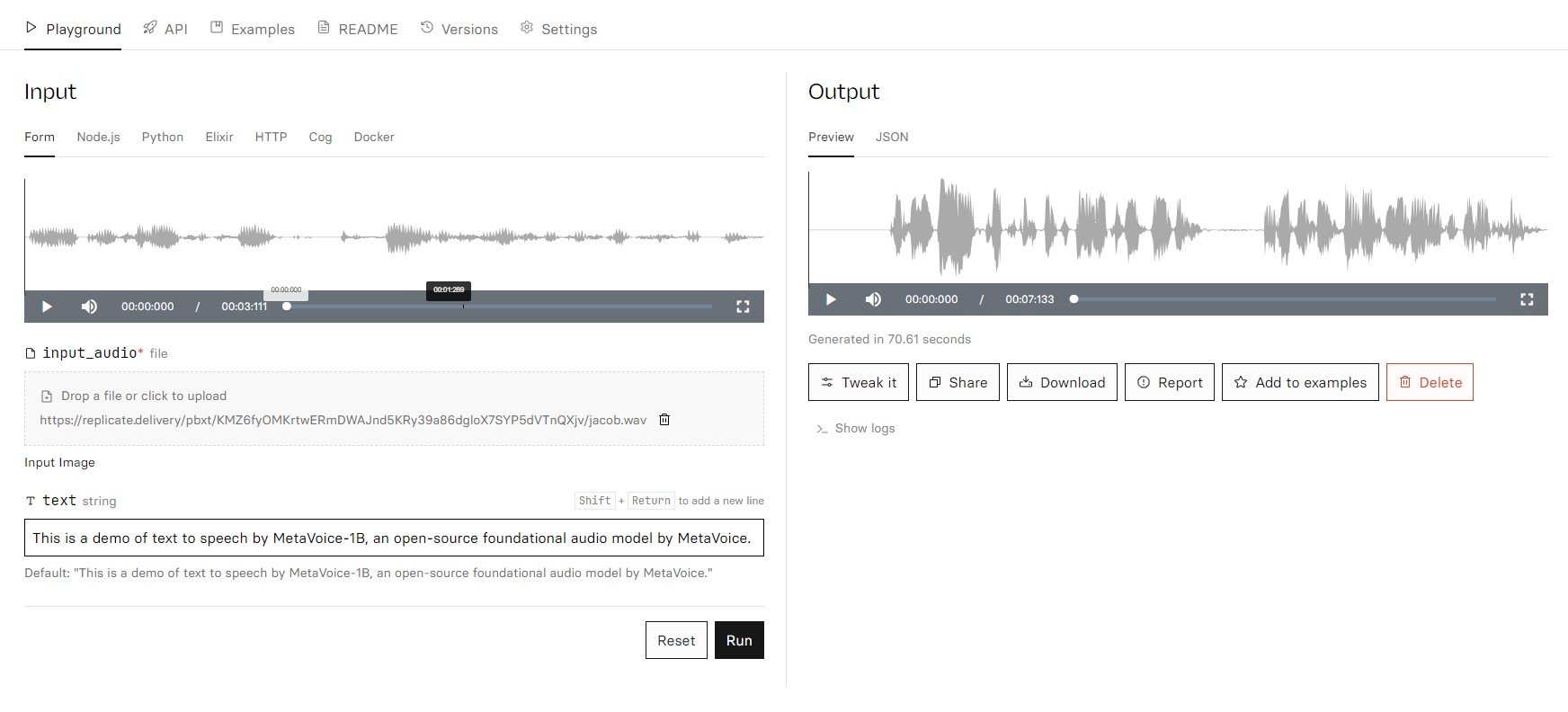
camenduru/metavoice
MetaVoice-1B: 1.2B parameter base model trained on 100K hours of speech

zsxkib/dia
Dia 1.6B by Nari Labs, Generates realistic dialogue audio from text, including non-verbal cues and voice cloning
lucataco/speaker-diarization
Segments an audio recording based on who is speaking (on A100)

grandlineai/instant-id-artistic
InstantID : Zero-shot Identity-Preserving Generation in Seconds. Using Dreamshaper-XL as the base model to encourage art...

philz1337x/clarity-pro-upscaler
The first creative upscaler which keeps identity. Stunning photorealistic results, realistic skin, and full creative con...

arielreplicate/deoldify_video
Add colours to old video footage.
wavespeedai/qwen-image
A 20B MMDiT model for next-gen text-to-image generation

xai/grok-imagine-image
SOTA image model from xAI

pellmellism/xkcd
epic xkcd comics

bria/fibo
SOTA Open source model trained on licensed data, transforming intent into structured control for precise, high-quality A...

jd7h/zero123plusplus
Turn an image into a set of images from different 3D angles

anthropic/claude-opus-4.6
Anthropic's most intelligent model with state-of-the-art coding, reasoning, and agentic capabilities

openai/gpt-4o-mini-transcribe
A speech-to-text model that uses GPT-4o mini to transcribe audio

nohamoamary/image-captioning-with-visual-attention
datasets: Flickr8k

makinsongary698/jh
No description available

lucataco/demofusion-enhance
Image to Image enhancer using DemoFusion
wan-video/wan-2.7-videoedit
Edit videos with natural language instructions using Alibaba's Wan 2.7 VideoEdit model

luma/ray-2-540p
Generate 5s and 9s 540p videos

lucataco/rembg-video
Video Background Removal
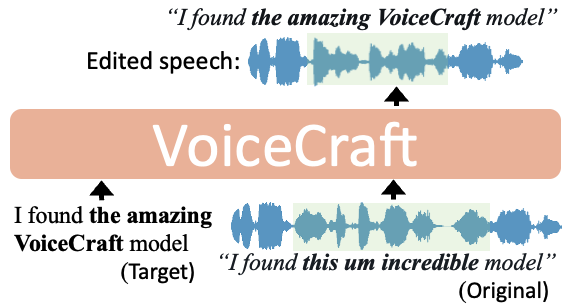
cjwbw/voicecraft
Zero-Shot Speech Editing and Text-to-Speech in the Wild

black-forest-labs/flux-pro-finetuned
Inference model for FLUX.1 [pro] using custom `finetune_id`
tencentarc/animesr
Real-World Super-Resolution Models for Animation Videos

leonardoai/motion-2.0
Create 5s 480p videos from a text prompt

zsxkib/animatediff-illusions
Monster Labs' Controlnet QR Code Monster v2 For SD-1.5 on top of AnimateDiff Prompt Travel (Motion Module SD 1.5 v2)

minimax/music-2.6
Generate full-length songs or instrumentals from a text prompt, with optional auto-generated lyrics

cuuupid/flux-lineart
Flux finetuned for black and white line art.

retro-diffusion/rd-animation
Style consistent animated pixel art sprite generation

adirik/dreamgaussian
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
runwayml/gen-4.5
State-of-the-art video motion quality, prompt adherence and visual fidelity

retro-diffusion/rd-tile
All the tools you need for generating pixel art tilesets

zylim0702/remove_bg
Best Human detection and Object Detection Background removal.

charlesmccarthy/animagine-xl
Animagine XL 2.0 is an advanced latent text-to-image diffusion model designed to create high-resolution, detailed anime ...

pollinations/real-basicvsr-video-superresolution
RealBasicVSR: Investigating Tradeoffs in Real-World Video Super-Resolution
lightricks/ltx-video-0.9.7-distilled
Faster slight quality reduction compared to LTX-Video 13b

zsxkib/pyramid-flow
Text-to-Video + Image-to-Video: Pyramid Flow Autoregressive Video Generation method based on Flow Matching

ibm-granite/granite-3.1-2b-instruct
Granite-3.1-2B-Instruct is a lightweight and open-source 2B parameter model designed to excel in instruction following t...

zsxkib/flux-music
🎼FluxMusic Text-to-Music Generation with Rectified Flow Transformer🎶
heygen/video-translate
Translate videos into over 150 languages

minimax/music-2.5
Generate full-length songs with vocals, lyrics, and rich instrumentation from a text prompt

lucataco/kontext-realearth
This Kontext LoRA turns basic satellite images into quality drone shots

cjwbw/face-align-cog
face alignment using stylegan-encoding

flux-kontext-apps/filters
Add simple filters to your images

levelsio/neon-tokyo
Take photos in the style of rainy Tokyo nights with neon lights

elevenlabs/v3
The most expressive Text to Speech model

prunaai/p-image-try-on
Virtual try-on. Put one or more garments onto a person photo while keeping their face, pose, and body.
zsxkib/thinksound
Generate contextual audio from video using step-by-step reasoning🎶
lucataco/smolvlm-instruct
SmolVLM-Instruct by HuggingFaceTB

elevenlabs/scribe-v2
Transcribe speech with ElevenLabs Scribe v2. 90+ languages, word-level timestamps, speaker diarization for up to 32 spea...

prunaai/hunyuan3d-2
hunyuan3d-2 optimised with the pruna toolkit: https://github.com/PrunaAI/pruna

lucataco/stable-diffusion-x4-upscaler
Stable Diffusion x4 upscaler model

luma/modify-video
Modify a video with style transfer and prompt-based editing

afterpeak/flux-slowed
Flux LORA to generate images in the style of the arworks used for sowed versions of a song

lucataco/flux-watercolor
A Flux LoRA trained on watercolor style photos

tmappdev/lipsync
Lipsync model using MuseTalk

halimalrasihi/flux-mystic-animals
Flux LoRA: Use "m1st1c" in your prompt to trigger this LoRA model.

cudanexus/ocr-surya
Surya is a document OCR toolkit that does:

justmalhar/flux-thumbnails
Generate 16:9 Thumbnails. Use prefix - `Thumbnail in the style of TOK`

lucataco/llama-3-vision-alpha
Projection module trained to add vision capabilties to Llama 3 using SigLIP

fofr/flux-minecraft-movie
Flux lora, use "MNCRFTMOV" to trigger image generation
pixverse/pixverse-v5.6
Latest video model from Pixverse with astonishing physics

flux-kontext-apps/impossible-scenarios
Experience impossible adventures and extreme scenarios from a single image

recraft-ai/recraft-v4.1
Recraft's latest image generation model, built around design taste. Strong prompt accuracy, art-directed composition, an...

sourceful/riverflow-2.0-fast
Agentic image model optimized for high-quality, fast generations supporting font control

sebastianbodza/flux_lora_retro_linedrawing_style_v1
No description available
justmalhar/flux-sketchnotes
Generates hand-drawn sketchnotes with great detail. Prompt Prefix: “A sketchnote in the style of TOK”

ibm-granite/granite-vision-4.1-4b
Granite Vision 4.1 4B is a vision-language model (VLM) that delivers frontier-level performance on structured document e...

0xtuba/archillect-lora
Generates images in the style of Archillect

ideogram-ai/layerize
Take a flat graphic, remove text, and get structured text layers back for editing and recomposing

aramintak/flux-koda
Flux lora, use "flmft style" to trigger the image generation

zsxkib/bsrgan
Upscale videos + images with BSRGAN

zsyoaoa/invsr
Arbitrary-steps Image Super-resolution via Diffusion Inversion

inworld/realtime-tts-2
Most expressive text-to-speech model from Inworld, with natural-language steering, real-time latency, and multilingual s...

zsxkib/animatediff-prompt-travel
🎨AnimateDiff Prompt Travel🧭 Seamlessly Navigate and Animate Between Text-to-Image Prompts for Dynamic Visual Narrative...
collectiveai-team/speaker-diarization-3
Segments an audio recording based on who is speaking

fofr/flux-80s-cyberpunk
A flux lora trained on a 1980s cyberpunk aesthetic

black-forest-labs/flux-2-klein-9b-base-lora
A version of FLUX.2 [klein] 9B-base that supports fast fine-tuned lora inference

recraft-ai/recraft-v4
Recraft's latest image generation model, built around design taste. Strong prompt accuracy, art-directed composition, an...
mirelo/video-to-sfx-v1
Generate synced sounds for any video, and return it with its new sound track

flux-kontext-apps/kontext-emoji-maker
Use kontext to turn any image into an emoji, using a lora by starsfriday
xai/grok-imagine-video-extension
Extend videos with xAI's Grok Imagine Video model. Provide a source video and describe what happens next.

jakedahn/flux-latentpop
flux-latentpop features vibrant backgrounds with grungy limited screenprinting color goodness.

qwen-edit-apps/qwen-image-edit-plus-lora-next-scene
Next Scene – “Next beat” cinematic edits that keep subject identity while steering to the next camera move via the Next ...

wavespeedai/hunyuan-video-fast
Accelerated inference for HunyuanVideo with high resolution (1280x720), a state-of-the-art text-to-video generation mode...

zsxkib/flash-face
FlashFace: Human Image Personalization with High-fidelity Identity Preservation
awilliamson10/meta-nougat
Nougat: Neural Optical Understanding for Academic Documents

elevenlabs/turbo-v2.5
High quality, low latency text to speech in 32 languages

moonshotai/kimi-k2-thinking
Kimi K2 Thinking is the latest, most capable version of an open-source thinking model.

pwntus/flux-albert-einstein
A fine-tuned FLUX.1 model. Use trigger word "EINSTEIN". Created with ReFlux (https://reflux.replicate.dev).

openai/gpt-5-pro
The smartest, fastest, most useful model yet, with built-in thinking that puts expert-level intelligence in everyone’s h...

elevenlabs/music
Compose a song from a prompt or a composition plan

cjwbw/docentr
End-to-End Document Image Enhancement Transformer

ibm-granite/granite-embedding-278m-multilingual
Granite-Embedding-278M-Multilingual is a 278M parameter model from the Granite Embeddings suite that can be used to gene...

codingdudecom/flux-kontext-stencil-lora
Stencil maker - create a black and white stencil image from any photo

lucataco/extract-audio
Simple tool to extract audio from a video file

lucataco/ip_adapter-face-inpaint
A combination of ip_adapter SDv1.5 and mediapipe-face to inpaint a face

lucataco/controlnet-tile
Controlnet v1.1 - Tile Version

camenduru/lgm
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation

fofr/flux-mjv3
Flux lora trained on Midjourney v3 outputs from 2022, use "a dream, in the style of MJV3" to trigger generation, also tr...
lightricks/ltx-2-retake
Take any shot and edit specific sections. Rephrase, change the action, camera angles and more

veryvanya/flux-ps1-style
Flux lora, use "ps1 game screenshot" to trigger image generation

lucataco/ollama-llama3.2-vision-11b
Ollama Llama 3.2 Vision 11B

bria/product-shadow
Add consistent, customizable shadows to product cutouts for enhanced visual appeal
kwaivgi/kling-v1.5-pro
Generate 5s and 10s videos in 1080p resolution at 30fps

lucataco/ollama-llama3.2-vision-90b
Ollama Llama 3.2 Vision 90B

prunaai/sdxl-lightning
This is the fastest sdxl-lightning endpoint in the world on A100, contact us for more at pruna.ai

jbilcke/flux-dev-panorama-lora
A flux lora for panoramas, use 21:9 and "HDRI panoramic view of TOK" to trigger image generation

zeke/ziki-flux
A Flux fine-tune of https://replicate.com/zeke the real-life human. Use "ZIKI" in the prompt to activate the trained sty...

fofr/flux-color
Flux lora, use "CLR" to trigger image generation

fofr/flux-mona-lisa
Flux lora, use the term "MNALSA" to trigger generation

qwen-edit-apps/qwen-image-edit-plus-lora-relight
Relight – Soft, curtain-filtered relighting that repaints the scene with golden-hour or moody tones using the Relight Lo...

sebastianbodza/flux_aquarell_watercolor_style
A watercolor Aquarell style lora for flux

sakemin/musicgen-stereo-chord
Generate music in stereo, restricted to chord sequences and tempo

zsxkib/aura-sr
AuraSR: GAN-based Super-Resolution for real-world

openai/o1-mini
A small model alternative to o1

pixverse/pixverse-v3.5
Create videos in as little as 10 seconds. 5s or 8s videos at 360p, 540p, 720p or 1080p.

qwen-edit-apps/qwen-image-edit-plus-lora-photo-to-anime
Photo to Anime – Stylized conversion that turns photos into crisp cel-shaded anime frames using the Photo-to-Anime LoRA.
zsxkib/multitalk
Audio-driven multi-person conversational video generation - Upload audio files and a reference image to create realistic...

hyper3d/rodin
Generate complex 3D models from images with Rodin Gen-2

fofr/0_1-webp
Make pictures of an AI character named 0_1.webp

levelsio/lomography
Take photos in the style of a Lomography camera

genmoai/mochi-1
Mochi 1 preview is an open video generation model with high-fidelity motion and strong prompt adherence in preliminary e...
prunaai/p-video-animate
p-video-animate animates a reference image with the motion and audio of a source video. Optimized for speed and cost — 5...

adirik/wonder3d
Generates 3D assets from images
wan-video/wan-2.7-t2v
Generate videos with audio from text prompts using Alibaba's Wan 2.7 model. 1080p, up to 15 seconds, with audio synchron...

sakemin/musicgen-chord
Generate music restricted to chord sequences and tempo

cuuupid/marker
Convert scanned or electronic documents to markdown, very very very fast

zsxkib/hunyuan-video2video
A state-of-the-art text-to-video generation model capable of creating high-quality videos with realistic motion from tex...

lucataco/magnet
MAGNeT: Masked Audio Generation using a Single Non-Autoregressive Transformer

anthropic/claude-sonnet-4.6
Claude Sonnet 4.6 from Anthropic: a full upgrade to coding, computer use, long-context reasoning, agent planning, knowle...

flux-kontext-apps/depth-of-field
Bring your subjects into focus with FLUX.1 Kontext [pro]

cjwbw/parler-tts
lightweight text-to-speech (TTS) model, trained on 10.5K hours of audio data
vidu/q3-pro
High-fidelity video generation with text-to-video, image-to-video, and start-end-to-video modes. Up to 16 seconds at 108...
zsxkib/idefics3
Idefics3-8B-Llama3, Answers questions and caption about images

cuuupid/cogvideox-5b
Generate high quality videos from a prompt

lightricks/ltx-video-0.9.7
DiT-based 13b video generation model, creating 30fps video

brunnolou/flux-texture-abstract-painting
Turn anything into an abstract fine art masterpiece 🎨

openai/dall-e-2
The original classic DALLᐧE 2

wan-video/wan-2.7-r2v
Generate videos from reference images or clips while preserving subject identity using Alibaba's Wan 2.7 reference-to-vi...

aramintak/mooniverse
Trigger phrase: surreal style

prunaai/p-image-lora
Use trained LoRAs from the https://replicate.com/prunaai/p-image-trainer. Find or contribute LoRAs here https://huggingf...
cjwbw/controlvideo
Training-free Controllable Text-to-Video Generation

markredito/90sbadtrip
A LoRA for Flux.1 Dev to re-create really bad and trippy CGI from the 90s.

zsxkib/uform-gen
🖼️ Super fast 1.5B Image Captioning/VQA Multimodal LLM (Image-to-Text) 🖋️
fofr/not-real
Make a very realistic looking real-world AI video

willywongi/donut
Extract structured data from receipt images using Donut 🍩 (Document Understanding Transformer)
xai/grok-speech-to-text
Transcribe audio to text with xAI's Grok. Handles 25 languages, word-level timestamps, speaker diarization, multichannel...
bytedance/dreamactor-m2.0
Animate any character, humans, cartoons, animals, even non-humans, from a single image + driving video

lucataco/omnigen2
OmniGen2: a powerful and efficient unified multimodal model

felixyifeiwang/eom-phase1
No description available

fofr/flux-2004
A flux dev lora fine-tuned on bad 2004 digital photography

qwen-edit-apps/qwen-image-edit-plus-lora-upscale
Upscale – Detail-loving upscale/restore pass that sharpens textures and color fidelity with the Upscale LoRA.

recraft-ai/recraft-v4-pro
Recraft's latest image generation model at ~2048px resolution. Same design taste and prompt accuracy as V4, with higher ...

fofr/kontext-ps1
FLUX Kontext fine-tune that let's you restyle any image as a PS1 or PS2 video game

darionaviar/cinthia
No description available
kwaivgi/kling-o1
Modify an existing video through natural-language commands, changing subjects, environments, and visual style while pres...
bytedance/video-upscaler
Upscale and enhance video up to 4K at 60fps, with scene-aware presets for AI-generated content, short dramas, UGC, and f...

lucataco/flux-vlta
A Flux finetune of an AI character named: Violeta
prunaai/p-video-replace
p-video-replace swaps the person in a video with one from a reference image, keeping motion, timing, camera, and scene e...
lightricks/audio-to-video
Use audio input with an image or prompt to generate videos
anthropic/claude-fable-5
Claude Fable 5 from Anthropic: the next generation of intelligence for the hardest knowledge work and coding problems.

replit/replit-code-v1-3b
Generate code with Replit's replit-code-v1-3b large language model
bria/video-remove-background
Automatically remove backgrounds from videos -perfect for creating clean, professional content without a green screen.

camenduru/one-shot-talking-face
one-shot-talking-face-replicate

karlvann/karl
No description available

shapestudio/floating-flux
Retro style Flux Lora

qwen-edit-apps/qwen-image-edit-plus-lora-fusion
Fusion – Product/object blending that fixes perspective and lighting so the subject melts into a new background via the ...

krea/krea-2-medium
Foundation image model from Krea, tuned for expressive illustration, anime, and painterly styles. Fast and consistent ac...
philz1337x/crystal-video-upscaler
High-precision video upscaler optimized for portraits, faces and products. One of the upscale modes powered by Clarity A...

fofr/flux-neo-1x
Flux lora, fine tuned on NEO-1X robot, use "NEO1X" to trigger image generation

luma/ray-3.2
Luma's reasoning video model. Generates cinematic 5s or 10s video from text or images, with native HDR and EXR export fo...

aramintak/enna-sketch-style
A hand drawn sketch style LoRA

adirik/flux-fantasy-architecture
Flux lora, use "in the style of FNTSYRCH" to trigger

davisbrown/photo-glow
Flux LoRA, trigger style with "in the style of TOK", Photographic images with a beautiful glow

fofr/deprecated-batch-image-captioning
A wrapper model for captioning multiple images using GPT, Claude or Gemini, useful for lora training

ideogram-ai/ideogram-v4-quality
The highest quality Ideogram v4 model. v4 creates images with stunning realism, creative designs, and consistent styles

bria/product-cutout
Precise AI-powered product cutout with 256-level transparency for eCommerce

adirik/imagedream
Image-Prompt Multi-view Diffusion for 3D Generation

linoytsaban/flux-yarn-art
Flux lora, use "yarn art style" to trigger image generation

heygen/lipsync-precision
High-accuracy lip-sync: replace or dub audio on any video with avatar-inference lip sync

fermatresearch/spanish-f5-tts
A F5-TTS fine-tuned for Spanish

fofr/flux-jwst
Flux fine-tuned on JWST deep space astrophotography

aramintak/flux-film-foto
Flux lora in a realistic film style. Use flmft photo style to trigger the image generation.
gauravk95/sadtalker-video
Make your video talk anything
kwaivgi/kling-v1.5-standard
Generate 5s and 10s videos in 720p resolution at 30fps

recraft-ai/recraft-v4.1-svg
Generate production-ready SVG vector images from text prompts. Recraft V4.1's design taste applied to vector output — cl...
vidu/q3-turbo
Fast video generation with text-to-video, image-to-video, and start-end-to-video modes. Up to 16 seconds at 1080p with s...

andreasjansson/flux-goo
FLUX.1 [dev] trained on the Replicate goo

lucataco/flux-syd-mead
Flux finetune trained on Syd Mead concept art for Blade Runner

qunash/iphone_camera_style
Trained on iPhone photos of Tokyo. Add "shot on TOKSTYL camera" at the end of your prompts.

lucataco/wan-2.1-1.3b-vid2vid
Wan 2.1 1.3b Video to Video. Wan is a powerful visual generation model developed by Tongyi Lab of Alibaba Group

aramintak/flux-frosting-lane
Flux lora, use "frstingln illustration" to trigger the image generation

datacte/flux-synthetic-anime
Flux lora, use "1980s anime screengrab", "VHS quality", or "syntheticanime" to trigger image generation

adirik/texture
Generate texture for your mesh with text prompts

fofr/kontext-fix-jpeg-compression
Use this flux-kontext fine-tune to fix JPEG compression artifacts
bytedance/dolphin
Document Image Parsing via Heterogeneous Anchor Prompting

black-forest-labs/flux-2-klein-4b-base-lora
A version of FLUX.2 [klein] 4B-base that supports fast fine-tuned lora inference

genericdeag/comic-style
No description available

elevenlabs/v2-multilingual
Generate multilingual text-to-speech audio in over 30 languages

recraft-ai/recraft-v4-svg
Generate production-ready SVG vector images from text prompts. Recraft V4's design taste applied to vector output — clea...

lucataco/csm-1b
CSM (Conversational Speech Model) is a speech generation model from Sesame that generates RVQ audio codes from text and ...
fishwowater/trellis2
TRELLIS.2: Native and Compact Structured Latents for 3D Generation

fofr/flux-y2k
Flux lora, use "Y2K" to trigger image generation

adirik/mvdream
Generate 3D assets using text descriptions

lucataco/singing_voice_conversion
Amphion Singing Voice Conversion: DiffWaveNetSVC

zsxkib/stable-video-face-restoration
SVFR: A Unified Framework for Generalized Video Face Restoration

buildingwithai/ai-jo
No description available

janghaludu/kocchaga
Flux finetune that is trained on Glitches generated by a Processing Script ( In Readme ), WIP.

fofr/flux-bad-70s-food
Flux dev lora trained on photos of 1970s food

recraft-ai/recraft-v4.1-pro
Recraft's latest image generation model at ~2048px resolution. Same design taste and prompt accuracy as V4.1, with highe...

fofr/flux-macro-texture
Flux lora, trained on macro textures, use "MCROTX" to trigger image generation

cddietz/michael
No description available

jayenkai/derek
Cartoon Derek is happy, sometimes
sync/react-1
Realistic lipsync with refined human emotion capabilities

bria/product-packshot
Transform any product photo into professional 2000x2000px packshots with optimal positioning

tjrndll/flux-dev-woodcut-prints
No description available

fofr/flux-cassette-futurism
Flux lora, use "cassette futurism" to trigger generation

minimax/music-cover
Reimagine any song in a different style — change voice, instruments, genre, and arrangement while keeping the original m...

andreasjansson/flux-shapes
Flux LoRA trained on generated images of random shapes
heygen/video-agent
Turn a text prompt into a complete, polished video with AI-generated script, avatar presenter, voiceover, visuals, and e...

fofr/flux-cyberpunk-typeface
Flux lora by AggravatingScree7189, use "cyberpunk typeface" to trigger image generation

fofr/flux-spitting-image
Flux lora, use "spitting image caricature" to trigger image generation

ugleh/flux-dev-lora-dixit
Flux LoRA, use 'DIXIT' to trigger generation, creates images with the art style of the board game DIXIT.

camenduru/lgm-ply-to-glb
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
mickeybeurskens/latex-ocr
Optical character recognition to turn images of latex equations into latex format.
lucataco/split-screen-video
Combines two videos into a single split-screen layout

fofr/flux-cross-section
Flux lora, use "XSEC cross section" to trigger image generation

qunash/circassian-culture-flux-3000-steps
A FLUX.1 model fine-tuned on Circassian culture images

marckohlbrugge/flux-wojak-v2
No description available

oshtz/flux-plastic3d
flux.1 'plastic3d' style lora

allthingsai69/sydneysweeney
Dream-girl Sydney Sweeney ready for your creative liberties!

fermatresearch/dpo-sdxl-controlnet-lora
DPO-SDXL Canny controlnet with LoRA support.
justmalhar/flux-mobile-ui
Generate detailed mobile app user interfaces (UIs) using prefix “MOBIUI containing..” in 4-15 steps.

recraft-ai/recraft-v4-pro-svg
Generate detailed SVG vector graphics from text prompts. Recraft V4 Pro's design taste with more geometric detail and fi...

rainer1966-de/flux_rainer
No description available

fofr/flux-wrong
Flux lora, use “WRNG” to trigger image generation
bytedance/seedance-2.0-mini
A lower-cost variant of Seedance 2.0 for high-volume video generation with multimodal inputs and native audio.

fofr/kontext-0_1-webp
No description available

darionaviar/dario_naviar
No description available

tokaito14/fullbody
Model

jamorphy/moebius-flux-lora
No description available

cdreier/golang-gopher-flux
a fine tuned gopher flux LoRA - the trigger word is GOGOPH
nateraw/autotune
pitch correction on your voice
alibaba/happyhorse-1.1
Alibaba's Happy Horse 1.1 generates videos from text, animates a single image, or builds a video from multiple reference...

ori299/mc-thumbnails-v1
No description available
prunaai/vace-1.3b
This is VACE-1.3B model optimised with pruna ai. Wan2.1 VACE is an all-in-one model for video creation and editing.

sourceful/riverflow-v2.5-fast
Speed-optimized variant of Riverflow 2.5 for production and latency-sensitive workflows

cuuupid/qwen2-vl-2b
SOTA open-source model for chatting with videos and the newest model in the Qwen family

ideogram-ai/ideogram-v4-balanced
Balance speed, quality and cost. Ideogram v4 creates images with stunning realism, creative designs, and consistent styl...

flux-kontext-apps/restyle-video-frame
Use flux-kontext-pro to change the first or last frame of a video. Useful to use as inputs for restyling an entire video...

andreasjansson/flux-me
flux trained on me

anthropic/claude-sonnet-5
Anthropic's most agentic Sonnet model, bringing frontier-level coding and tool use at Sonnet's speed and price

nicolas7894/flux-undraw
Undraw Illustration Generator

intelligent-utilities/html-to-image
No description available

heygen/lipsync-speed
Fast lip-sync: replace or dub audio on any video with quick audio-driven lip sync

tahercoolguy/video_background_remover_appender
Remove Background of video and add yours

tokaito14/portrait
No description available

lucataco/pheme
Pheme generates a variety of conversational voices in 16 kHz for phone-call applications

krea/krea-2-large
Krea's flagship foundation image model. Larger and more flexible than Krea 2 Medium, with particular strength in photore...

lucataco/deep3d
Deep3D: Real-Time end-to-end 2D-to-3D Video Conversion, based on deep learning

fofr/kontext-long-exposure-for-water
Edit photos of water to be a long exposure using this kontext fine-tune

platform-kit/mars5-tts
A novel speech model for insane prosody.

mandelavybe/jungkook
No description available
heygen/avatar-iv
Create realistic talking avatar videos from text with HeyGen's Avatar IV engine

recraft-ai/recraft-v4.1-pro-svg
Generate detailed SVG vector graphics from text prompts. Recraft V4.1 Pro's design taste with more geometric detail and ...

digitaljohn/urban-narrative
No description available

andreasjansson/wan-1.3b-inpaint
Inpainting and video2video experiments with Wan 2.1

codingfu/bayc
No description available

evtn/pouyippie
A flux.1 fine-tune trained on pictures of a pou plush toy. Trigger is "pouyippie"

juliananev/frutiger-aero
Create your very own iconic frutiger aero inspired images!

sourceful/riverflow-v2.5-pro
Top-quality agentic image model with multi-step reasoning, candidate scoring, and adjustable thinking effort

dcamsdev/klm-lora-flux
Creates realistic KLM flight attendants

arcanite24/animation2k-flux
Flux lora inspired by early 2000s animation movies, use 1.2 guidance

fofr/qwen-fantasy-art
Qwen fine-tuned on fantasy art

fofr/qwen-midjourney-v3
Qwen fine-tuned on Midjourney v3 images

aramintak/linnea-flux-beta
An original character LoRA

nicknaskida/whisper-diarization
⚡️ Insanely Fast audio transcription | whisper large-v3 | speaker diarization | word & sentence level timestamps | promp...

fofr/flux-pixar-cars
No description available

adirik/mvdream-multi-view
Multi-view image generation with MVDream

oshtz/flux-celpast
flux.1 'celestial pastel' lora

shapestudio/nihon-flux
Fine tuned Lora Japanese style reference. Defaults to traditional red, grey and blue.

valllllex/cartoonia_3d
Restyling the classic cartoon and comic book characters into a soft painterly 3D style. FLUX Kontext Lora

chiasabah/flux-pepe
flux-pepe(Prompt-Enabled Picture Evolution) generates fictional internet parody characters.

emunozhern/fluxtok
No description available

sourceful/riverflow-2.0-refsr
Render product images with 100% accuracy and environmental blending

recraft-ai/recraft-v4.1-utility
A faster, lighter Recraft image generation model optimized for high-volume and production pipelines. Same design taste a...

ferunelli/chadmeme
No description available

jiht76/mindyflux
No description available

ckizer/ckizer-64
This model generates photo portraits of Court Kizer. Use the trigger word "ckizer" in your prompt. EX: "A professional p...

adirik/text2tex
[Non-commercial] Generate texture for 3D assets using text descriptions

zeke/tarot-flux
This model is not great. Check out this other one that's better: https://replicate.com/apolinario/flux-tarot-v1

recraft-ai/recraft-v4.1-utility-pro
A faster, lighter Recraft image generation model at ~2048px resolution, optimized for high-volume production. Design tas...

jan890/flux_dev_ascii_art
This AI ASCII Image Generator converts text prompts into detailed ASCII art images. Just include the trigger word "ASCII...

elevenlabs/flash-v2.5
ElevenLabs's fastest speech synthesis model

qwen/qwen-image-lora-trainer-legacy
Fine-tunable Qwen Image model with exceptional composition abilities - train custom LoRAs for any style or subject

ctrimm/backyard-sports-character-creator
Creates Outputs in the Style of Backyard Sports Characters

sylvesteraswin/sylvester-flux-selfie
No description available

s76354m/fluxfinetune
No description available

deepfates/flux-hot-zuck
A fine-tuned FLUX.1 model. Use trigger word "ZUCK". Created with ReFlux (https://reflux.replicate.dev).

lucataco/flux-queso
A Flux LoRA trained on photos of Jake's dog: Queso

lucataco/minicpm-v-4
MiniCPM-V 4.0 has strong image and video understanding performance

lisandroe/loralisandro
No description available

scmdr/ai_graphic
No description available

jfobrien29/flux-us-national-parks
Generate photos like old school US National Park Posters

aj1357/ai-tshirt-mockup
No description available

advoworks/lokidog
No description available
fiolinuda/fiona
No description available

carlosperz88/teslacyberbeast
No description available

okostadsjunior/ninicollyloli
No description available

garyvoo/person2_new
No description available

fofr/flux-tessellate
No description available

alexvoorheesmusic/yanisse
No description available
cjwbw/canary-1b
Nvidia Automatic speech-to-text recognition (ASR) in 4 languages (English, German, French, Spanish)

rerm06/flux-dev-lora-rene
No description available
bria/video-increase-resolution
Upscale videos up to 8K output resolution. Trained on fully licensed and commercially safe data.

koratkar/miyazaki-watercolor
Hayao Miyazaki watercolor sketch LoRA

prunaai/p-image-trainer
Fast LoRA trainer for p-image, a super fast text-to-image model developed by Pruna AI. Use LoRAs here: https://replicate...

shapestudio/wild-flux
Edward Hopper(realist painter) inspired Flux Lora

fofr/flux-beyond-horizon
No description available

reve/reve-2.1
Generate and edit images from text and reference images with Reve 2.1
runwayml/aleph-2
Edit one frame to update an entire video. Aleph 2.0 is Runway's in-context video editor: longer clips (up to 30s), multi...

lipex157zoi/lipexbradok
No description available

igorriti/flux-fileteado
Fileteado porteño style for Flux

roberthein/modelname-new
No description available

mofleck/arcodeltriunfosjv1
No description available

bonapartee/thumbnail-generator
No description available

wowohello/fat_funjin
No description available

geobotsar81/geobotsar-flux-2
No description available

openai/gpt-5.6-sol
OpenAI's GPT-5.6 flagship tier, built for complex professional work, coding, and deep multi-step reasoning.

adirik/udop-large
Performs document image classification, document parsing and document visual question answering

tokaito14/art
No description available

szdavid11/ola-scooter
No description available

shapestudio/portra-800-flux
Flux Lora inspired by Kodak Portra 800

witzelfitz/gardenflux
No description available

aperture-2/hido
No description available

julienhypeer/julienetoke
Model fine tuned avec des photos de moi avec casquette, prises de face du dossier "Shooting miniatures décembre 2023"

topazlabs/image-colorization
Image colorization model from Topaz Labs

idvorkin/idvorkin-flux-lora-1
No description available

lucataco/qwen-davinci
Qwen-image fine-tuned on Drawings by Leonardo da Vinci

ccchot-osk103/pai_qwen_21102568
a young lady name Pai

prestoncreed/flux-spongebob
Fine-Tuned on spongebob environment/aesthetic images. Use "in the SPONGE world" to get best results.

jarvis-labs2024/console_cowboy_flux
No description available

topazlabs/dust-and-scratch-v2
Remove dust and scratches from old photos

benj-edwards/dads-uppercase-2500-steps
A recreation of my dad's uppercase engineer-style handwriting.

sisyphos55/adsgenerator
No description available

dunaevai135/tst_svt3
No description available

someone12dd/muskoil1
No description available

lucataco/bulk-video-caption
Video Preprocessing tool for captioning multiple videos using GPT, Claude or Gemini

fofr/flux-myst
Flux lora based on the original Myst video game

okturan/flux-yesilcam
Creates images similar to scenes found in Yeşilçam movies

paulbasic/flux_paulh
a private model to play around and create fun

lucataco/video-split
Simple tool to split apart a video into snippets

kshitijagrwl/pii-extractor-llm
PII Data Extraction from Text

lucataco/kontext-meta-cars
Change your car into a CDMX Meta Car

ludocomito/flux-caravaggio
No description available

derrrick/flux-70s-bands
lora for 70s band aesthetics

fofr/flux-hyundai-n-vision-74
Flux lora, use "Hyundai N Vision 74 car" to trigger image generation

zzyjay/icedevsfm
No description available

ah77ac/majestyrabbit-flux-lora
No description available

0xdeadd/flux-your-model-name
A fine-tuned FLUX.1 model

fesilva196/lipex
A man

jakedahn/flux-soviet-controlrooms
Flux.1 fine-tune on soviet-era controlrooms

dunaevai135/tst2_d
No description available

markbland82/mjbstyle1
No description available

sigil-wen/laika-flux-lora
A FLUX.1 [dev] LoRA trained on Laika, Julia's dog

lucataco/apollo-3b
Apollo 3B - An Exploration of Video Understanding in Large Multimodal Models

joshelgar/rssmurryflux
No description available

gajendrajha09/fluxloramimi
No description available

szdavid11/kellogs-chocos
No description available
bria/video-erase-object
A high-fidelity capability for erasing unwanted objects, people, or visual elements from videos while maintaining aesthe...

shridharathi/ghibli-vid
Make a video of anything in Studio Ghibli style

s-clementc/manon
No description available

tylerbishopdev/retylerv2
Another Tyler; custom to your liking

heygen/avatar-v
Create realistic talking avatar videos from text with HeyGen's Avatar V engine — the newest, highest-quality avatar engi...

melaesse/ginevra
No description available

wuzoobia/bruna-portrait
Create stunning corporate portraits and executive headshots with photorealistic quality

hartmamt/flux-chicago-firesidebowl
Flux lora for scenes from famous Fireside Bowl, use "FRSBWL" to trigger

jarvis-labs2024/flux-appleseed
No description available

ibm-granite/granite-embedding-small-english-r2
Granite-embedding-small-english-r2 is a 47M parameter dense biencoder embedding model from the Granite Embeddings collec...
decart/lucy-edit-2
Edit and transform videos with text prompts and reference images. Style transfers, object replacement, character transfo...

abyssalsoul/cyberdad
No description available

therendercafe/therendercafegmailcom-sarahi-2595
A fine-tuned FLUX.1 model

lucataco/vid2webp
Convert your video into webp format (with looping)

dfrostar/hermes_kellybag
No description available

urieltac/polar-fleece
No description available

jarvis-labs2024/flux-raylene
No description available

sevensevenimages/rolxsub
No description available

cleexiang/jellycat
Flux Lora, use "jellycat toy" to trigger style like jellycat toy.

levelsio/brain-flakes-ai
Generate your own Brain Flakes with AI

fofr/qwen-my-subconscious
Qwen fine-tuned on trippy and vibrant FLUX Pro outputs

chatworks/luchtpods
No description available

someone12dd/libreintense
No description available

cristobalascencio/florentino
No description available

ibm-granite/granite-speech-4.1-2b
Granite Speech 4.1 2B is a compact and efficient speech-language model, specifically designed for multilingual automatic...

dunaevai135/tst_trn
No description available

uthana/text-to-motion-diffusion-v2
Generate 3D character animation data from a text prompt

fofr/flux-brighton-west-pier
Flux lora, trigger image generation with "west pier"

popovluka/luka-flux-lora-model
No description available

maikocode/ascii-style
Turn image into ASCII style. If you like this LoRA visit my app: YourAIPhotographer.com

bria/fibo-edit
FIBO-Edit brings the power of structured prompt generation to image editing

warf23/agrat_me
No description available

10xcrazyhorse/bonkfa
No description available

tokaito14/laura
Model

jcbianchi010/jeancbianchi
No description available

ihor-thecoach/ihor2
No description available

0xdeadd/vonda2
A fine-tuned FLUX.1 model
uthana/create-character-v1
Rig any 3D bipedal character mesh

damdam775/portraits_dialogues
Create RPG like expressive character portraits for in game dialogs.

enkey08/ganpatibappa
Ganpati image generation model trained on all Ganapati in Pune, India

sigil-wen/pepsi-flux
FLUX.1 [dev] LoRA trained on images of my cat Pepsi

banta2000/mytestmodel
No description available

mintkaori/seoulgi
No description available

cristobalascencio/wirra
No description available

kazdatahelp/llkm
No description available

mofleck/teslasemishipped
No description available

shridharathi/blueprint-qwen
No description available

fofr/qwen-2004
Qwen fine-tuned on bad photos from 2004

puribogdan/puri
No description available

warf23/ai_glasses
No description available

marcusschwarze/paul-mittelrheintaler
a public experiment with the AI generated figure of Paul Mittelrheintaler, a cool YouTuber in the middle Rhine Valley. C...

yuezheng2006/flux-lora-gyy
A Fulx1.D based lora for gaoyuanyuan,trigger word "gyy"

davidkwcheng/jessicayu02
No description available

esgfit/flux_andreas
No description available

alekseycalvin/acsoonr_flux
ACS token

grassyguru/archslra
No description available

imiroslav/ai_skoda_octavia
No description available
pbevan1/llama-3.1-8b-ocr-correction
LLaMA 3.1-8B, finetuned on a synthetic OCR dataset for superior OCR correction.

titouv/test_model3
No description available

anon987654321/ra2
No description available

fofr/qwen-bad-70s-food
Qwen fine-tuned on photos of bad 70s food

maybasmanphotographer/bmayb
No description available

ugleh/flux-dev-lora-painterdetective
Flux LoRA, use 'PRVDETC' to trigger generation, creates characters based on the art style of the board game Painter Dete...

ludocomito/flux-kuji
No description available

ummtushar/pilot
A fine-tuned FLUX.1 model v1.1

arthuryeti/dwiss-qwen-2
No description available

astronautdavid1/mad2-flux-lora
No description available

saysenbl/lisflux
No description available

andreaxricci/maradona
model fine-tuned with pictures of Maradona, the best soccer player of all times :)

dunaevai135/flux_lora_fungus
use TOK for rhizomorphic mycelium

maffuw/scrub-runners2
No description available

uthana/text-to-motion-vqvae-v1
Generate 3D character animation data from a text prompt

felixwky-code/sateur-lora
No description available

roadmaus/stillsuit
No description available

mckunkel/alexs
No description available

siamakf/petpatrol-joyi
No description available

guokai34370298/andy
No description available

maffuw/shakira
No description available

juddisjudd/ckh-flux-model
Lora of myself

matsnl65/langstonrichardson
No description available

justinwkukm/a_photo_of_wko
No description available

gaby94500/mamav
No description available

fofr/qwen-dark-art
Qwen fine-tuned on classical dark artwork

leosy-kingdom/leosy-earth2
No description available

fofr/qwen-william-blake
Qwen fine-tuned on the art of William Blake

mike-freeai/hx8y
No description available

ameureka/amazing
No description available

paullarin671/lawther
Flux lora of Alex Lawther, trained on 20 images. Trigger word:"lawther"

maubad/calaverasconllamas
No description available

juddisjudd/deriksen
No description available

zeke/ziki-2024-08-30
Use trigger word ziki-2024-08-30 to activate the trained LoRA style.

mike-gbenlandia/nigerian
No description available

ugleh/flux-dev-lora-fallguy2
No description available

joshelgar/andrwfrclgh
No description available

kazdatahelp/tql
No description available

jimmywong974/yoshi
No description available

fofr/qwen-black-sclera
No description available

rsjejonathanortiz/jonathan_heroes
No description available

juddisjudd/barricadettv
No description available

fuskio64/eugenito
Show a nice guy if you use the keyword Eugenito

johnseepps/hoodicon
No description available

qwen/qwen3-7-plus
Qwen3.7-Plus is Alibaba's cost-effective multimodal model with vision-language understanding, a 1 million token context ...

juddisjudd/kevine
No description available

fofr/qwen-n74
No description available

fofr/qwen-tron-ares
Qwen fine-tuned on TRON: ARES trailer

openai/gpt-5.6-terra
OpenAI's GPT-5.6 balanced tier, tuned for everyday production work at roughly half the cost of the flagship.

brucecris/bruce1
The first Bruce model.

yosun/camcorgi-qwern
a qwen lora that knows that CAM corgi looks like... https://replicate.delivery/xezq/Qeh4prhrfEjLOEoB2kgdzS98yArm2SoruIPG...

ccchot-osk103/happycat
No description available

ccchot-osk103/buacat
the grey tabby cat

openai/gpt-5.6-luna
OpenAI's GPT-5.6 cost-optimized tier, built for fast, high-volume, latency-sensitive workloads.

ccchot-osk103/moneycat
a cute and young orange British Shorthair cat