cjwbw/voicecraft
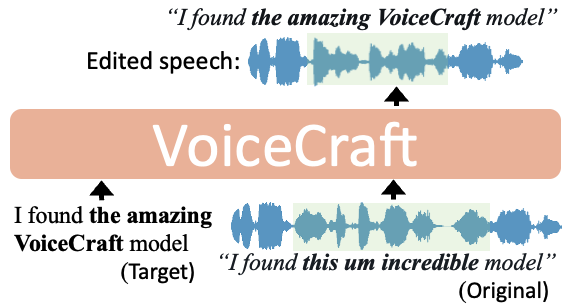
Zero-Shot Speech Editing and Text-to-Speech in the Wild
Capabilities
Cost
Community model (estimated from hardware time)
Input Parameters
| Name | Type | Description | Default | Constraints |
|---|---|---|---|---|
orig_audio* | string(uri) | Original audio file | — | — |
target_transcript* | string | Transcript of the target audio file | — | — |
cut_off_sec | number | Only used for for zero-shot text-to-speech task. The first seconds of the original audio that are used for zero-shot text-to-speech. 3 sec of reference is generally enough for high quality voice cloning, but longer is generally better, try e.g. 3~6 sec | 3.01 | — |
kvcache | integer | Set to 0 to use less VRAM, but with slower inference | 1 | 01 |
left_margin | number | Margin to the left of the editing segment | 0.08 | — |
orig_transcript | string | Optionally provide the transcript of the input audio. Leave it blank to use the WhisperX model below to generate the transcript. Inaccurate transcription may lead to error TTS or speech editing | "" | — |
right_margin | number | Margin to the right of the editing segment | 0.08 | — |
sample_batch_size | integer | Default value for TTS is 4, and 1 for speech editing. The higher the number, the faster the output will be. Under the hood, the model will generate this many samples and choose the shortest one | 4 | — |
seed | integer | Random seed. Leave blank to randomize the seed | — | — |
stop_repetition | integer | Default value for TTS is 3, and -1 for speech editing. -1 means do not adjust prob of silence tokens. if there are long silence or unnaturally stretched words, increase sample_batch_size to 2, 3 or even 4 | 3 | — |
task | string | Choose a task | "zero-shot text-to-speech" | speech_editing-substitutionspeech_editing-insertionspeech_editing-deletionzero-shot text-to-speech |
temperature | number | Adjusts randomness of outputs, greater than 1 is random and 0 is deterministic. Do not recommend to change | 1 | — |
top_p | number | Default value for TTS is 0.9, and 0.8 for speech editing | 0.9 | — |
voicecraft_model | string | Choose a model | "giga330M_TTSEnhanced.pth" | giga830M.pthgiga330M.pthgiga330M_TTSEnhanced.pth |
whisperx_model | string | If orig_transcript is not provided above, choose a WhisperX model for generating the transcript. Inaccurate transcription may lead to error TTS or speech editing. You can modify the generated transcript and provide it directly to orig_transcript above | "base.en" | base.ensmall.enmedium.en |
orig_audiorequiredstringOriginal audio file
target_transcriptrequiredstringTranscript of the target audio file
cut_off_secnumberOnly used for for zero-shot text-to-speech task. The first seconds of the original audio that are used for zero-shot text-to-speech. 3 sec of reference is generally enough for high quality voice cloning, but longer is generally better, try e.g. 3~6 sec
3.01kvcacheintegerSet to 0 to use less VRAM, but with slower inference
1left_marginnumberMargin to the left of the editing segment
0.08orig_transcriptstringOptionally provide the transcript of the input audio. Leave it blank to use the WhisperX model below to generate the transcript. Inaccurate transcription may lead to error TTS or speech editing
""right_marginnumberMargin to the right of the editing segment
0.08sample_batch_sizeintegerDefault value for TTS is 4, and 1 for speech editing. The higher the number, the faster the output will be. Under the hood, the model will generate this many samples and choose the shortest one
4seedintegerRandom seed. Leave blank to randomize the seed
stop_repetitionintegerDefault value for TTS is 3, and -1 for speech editing. -1 means do not adjust prob of silence tokens. if there are long silence or unnaturally stretched words, increase sample_batch_size to 2, 3 or even 4
3taskstringChoose a task
"zero-shot text-to-speech"temperaturenumberAdjusts randomness of outputs, greater than 1 is random and 0 is deterministic. Do not recommend to change
1top_pnumberDefault value for TTS is 0.9, and 0.8 for speech editing
0.9voicecraft_modelstringChoose a model
"giga330M_TTSEnhanced.pth"whisperx_modelstringIf orig_transcript is not provided above, choose a WhisperX model for generating the transcript. Inaccurate transcription may lead to error TTS or speech editing. You can modify the generated transcript and provide it directly to orig_transcript above
"base.en"db97f6312d4cUpdated: 7/25/202610.8K runs