sabuhigr/sabuhi-model
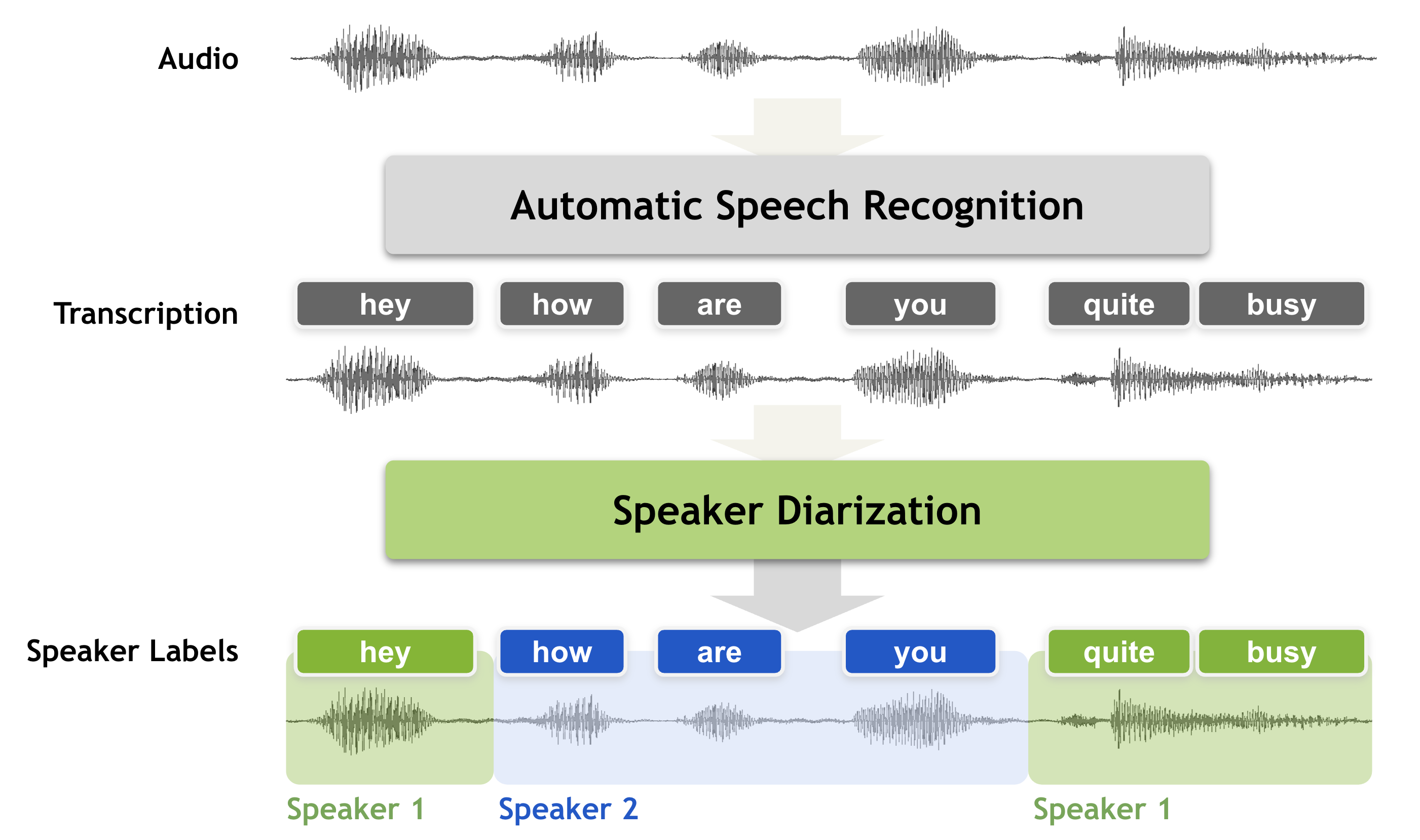
Whisper AI with channel separation and speaker diarization
Capabilities
Cost
Community model (estimated from hardware time)
Input Parameters
| Name | Type | Description | Default | Constraints |
|---|---|---|---|---|
audio* | string(uri) | Audio file | — | — |
hf_token* | string | Your Hugging Face token for speaker diarization | — | — |
language* | string | language spoken in the audio, specify None to perform language detection | — | afamarasazbabebgbnbobrbscacscydadeeleneseteufafifofrglguhahawhehihrhthuhyidisitjajwkakkkmknkolalblnloltlvmgmimkmlmnmrmsmtmynenlnnnoocpaplpsptrorusasdsiskslsnsosqsrsusvswtatetgthtktltrttukuruzviyiyozhAfrikaansAlbanianAmharicArabicArmenianAssameseAzerbaijaniBashkirBasqueBelarusianBengaliBosnianBretonBulgarianBurmeseCastilianCatalanChineseCroatianCzechDanishDutchEnglishEstonianFaroeseFinnishFlemishFrenchGalicianGeorgianGermanGreekGujaratiHaitianHaitian CreoleHausaHawaiianHebrewHindiHungarianIcelandicIndonesianItalianJapaneseJavaneseKannadaKazakhKhmerKoreanLaoLatinLatvianLetzeburgeschLingalaLithuanianLuxembourgishMacedonianMalagasyMalayMalayalamMalteseMaoriMarathiMoldavianMoldovanMongolianMyanmarNepaliNorwegianNynorskOccitanPanjabiPashtoPersianPolishPortuguesePunjabiPushtoRomanianRussianSanskritSerbianShonaSindhiSinhalaSinhaleseSlovakSlovenianSomaliSpanishSundaneseSwahiliSwedishTagalogTajikTamilTatarTeluguThaiTibetanTurkishTurkmenUkrainianUrduUzbekValencianVietnameseWelshYiddishYoruba |
compression_ratio_threshold | number | if the gzip compression ratio is higher than this value, treat the decoding as failed | 2.4 | — |
condition_on_previous_text | boolean | if True, provide the previous output of the model as a prompt for the next window; disabling may make the text inconsistent across windows, but the model becomes less prone to getting stuck in a failure loop | true | — |
initial_prompt | string | optional text to provide as a prompt for the first window. | — | — |
logprob_threshold | number | if the average log probability is lower than this value, treat the decoding as failed | -1 | — |
max_speakers | integer | Select 2 if record is stereo, 1 if is mono.Default is 1 for mono records | 1 | 12 |
min_speakers | integer | Select 2 if record is stereo, 1 if is mono.Default is 1 for mono records | 1 | 12 |
model | string | Choose a Whisper model. | "large-v2" | largelarge-v2 |
no_speech_threshold | number | if the probability of the <|nospeech|> token is higher than this value AND the decoding has failed due to `logprob_threshold`, consider the segment as silence | 0.6 | — |
patience | number | optional patience value to use in beam decoding, as in https://arxiv.org/abs/2204.05424, the default (1.0) is equivalent to conventional beam search | — | — |
suppress_tokens | string | comma-separated list of token ids to suppress during sampling; '-1' will suppress most special characters except common punctuations | "-1" | — |
temperature | number | temperature to use for sampling | 0 | — |
temperature_increment_on_fallback | number | temperature to increase when falling back when the decoding fails to meet either of the thresholds below | 0.2 | — |
transcription | string | Choose the format for the transcription | "plain text" | plain textsrtvtt |
translate | boolean | Translate the text to English when set to True | false | — |
audiorequiredstringAudio file
hf_tokenrequiredstringYour Hugging Face token for speaker diarization
languagerequiredstringlanguage spoken in the audio, specify None to perform language detection
compression_ratio_thresholdnumberif the gzip compression ratio is higher than this value, treat the decoding as failed
2.4condition_on_previous_textbooleanif True, provide the previous output of the model as a prompt for the next window; disabling may make the text inconsistent across windows, but the model becomes less prone to getting stuck in a failure loop
trueinitial_promptstringoptional text to provide as a prompt for the first window.
logprob_thresholdnumberif the average log probability is lower than this value, treat the decoding as failed
-1max_speakersintegerSelect 2 if record is stereo, 1 if is mono.Default is 1 for mono records
1min_speakersintegerSelect 2 if record is stereo, 1 if is mono.Default is 1 for mono records
1modelstringChoose a Whisper model.
"large-v2"no_speech_thresholdnumberif the probability of the <|nospeech|> token is higher than this value AND the decoding has failed due to `logprob_threshold`, consider the segment as silence
0.6patiencenumberoptional patience value to use in beam decoding, as in https://arxiv.org/abs/2204.05424, the default (1.0) is equivalent to conventional beam search
suppress_tokensstringcomma-separated list of token ids to suppress during sampling; '-1' will suppress most special characters except common punctuations
"-1"temperaturenumbertemperature to use for sampling
0temperature_increment_on_fallbacknumbertemperature to increase when falling back when the decoding fails to meet either of the thresholds below
0.2transcriptionstringChoose the format for the transcription
"plain text"translatebooleanTranslate the text to English when set to True
false29b6421db707Updated: 7/25/202625.5K runs